observation
我们前面讨论的都是单线程环境, 现在我们需要支持对这些数据结构的多线程访问安全来充分利用多核cpu并减少磁盘IO的等待.
redis和voltDB是单线程的;
A concurrency control protocol is the method that the DBMS uses to ensure “correct” results for concurrent operations on a shared object.
A protocol’s correctness criteria can vary:
- Logical Correctness: Can a thread see the data that it is supposed to see?
- Physical Correctness: Is the internal representation of the object sound?
还是lock和latch的区别:

我们现在用的还是latch
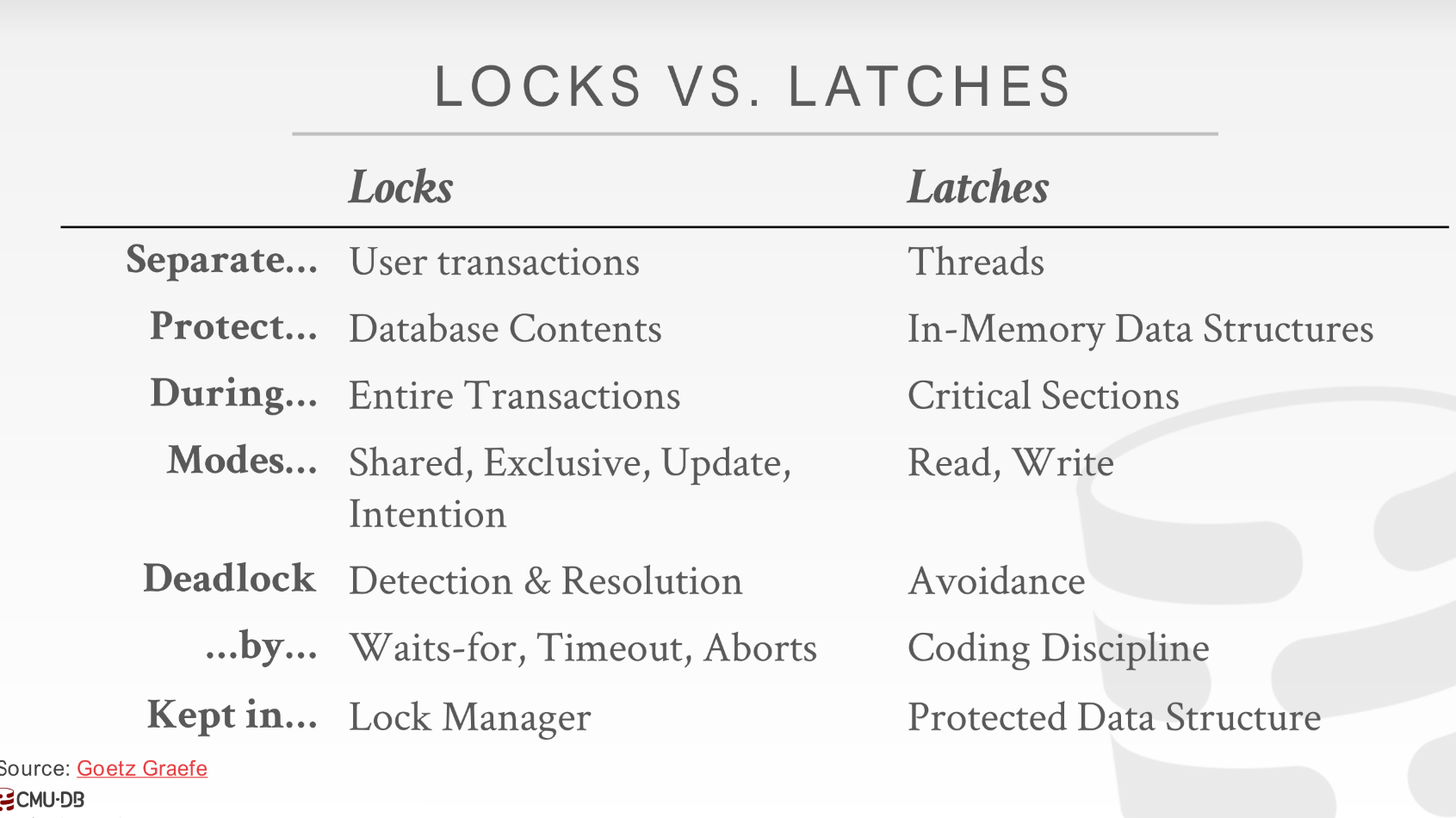
latch 的 模式, 可见写是排他的:

latch 实现
Blocking OS Mutex

Test and Set spin latch(TAS)

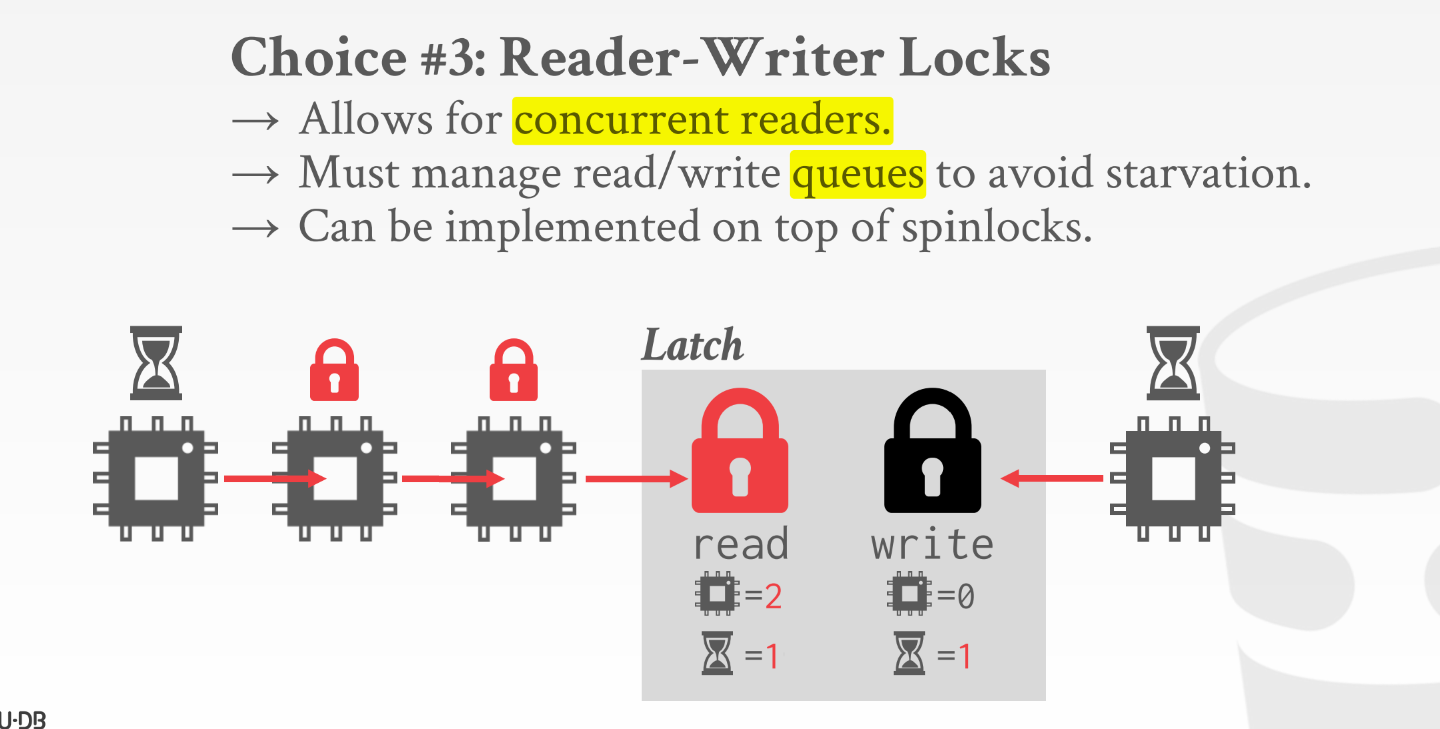
读写锁, 也是项目中会用到的锁
B+树多线程
b+树主要采用crabbing protocol来保证多线程安全

解释:
- 像螃蟹走路一样边走边释放
- 先拿parent page的latch
- 再拿孩子的latch
- 如果当前的操作不会引起孩子的分裂或者合并(这两种情况涉及到修改parent), 则释放parent的latch
- 具体引起孩子分裂或者合并的两种情况:
- 对于一个满的结点插入
- 对于刚好半满的结点删除

具体来说:
对于查找: 因为不存在冲突, 所以直接从root开始, 拿孩子, 释放root, 再拿孩子, 释放parent, 如此迭代, 知道叶子节点, 最后只拿了叶子page的read latch;
对于插入删除: 从root开始往叶子走, 一路上拿Write latch, 走到**孩子(非叶子!!!)**后检查孩子是否安全(即不会分裂或者合并): 如果安全, 则释放所有祖先的latch
例子:
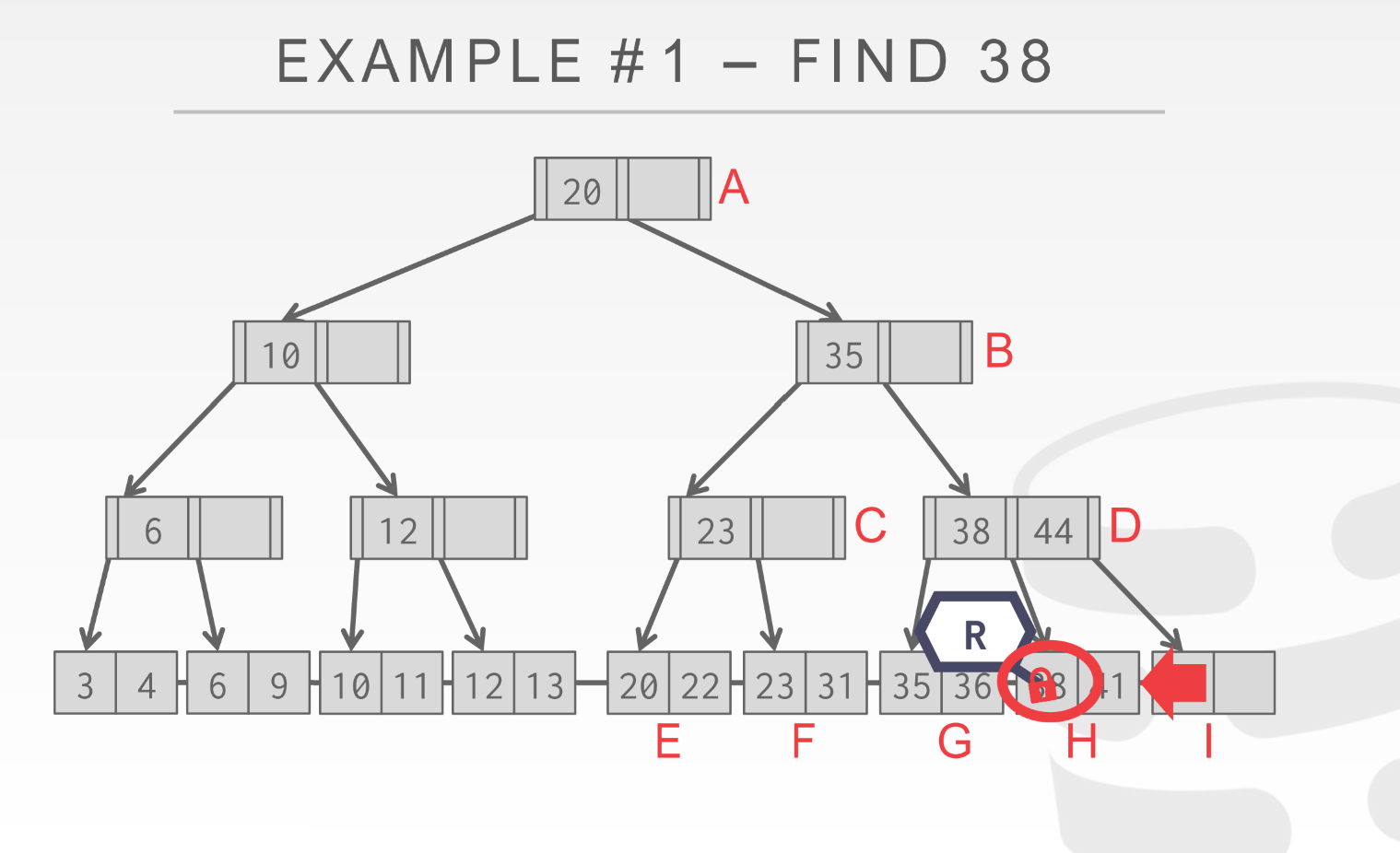
可见查找38, 到达叶子节点的时候只拿了一个叶子结点的Read latch;
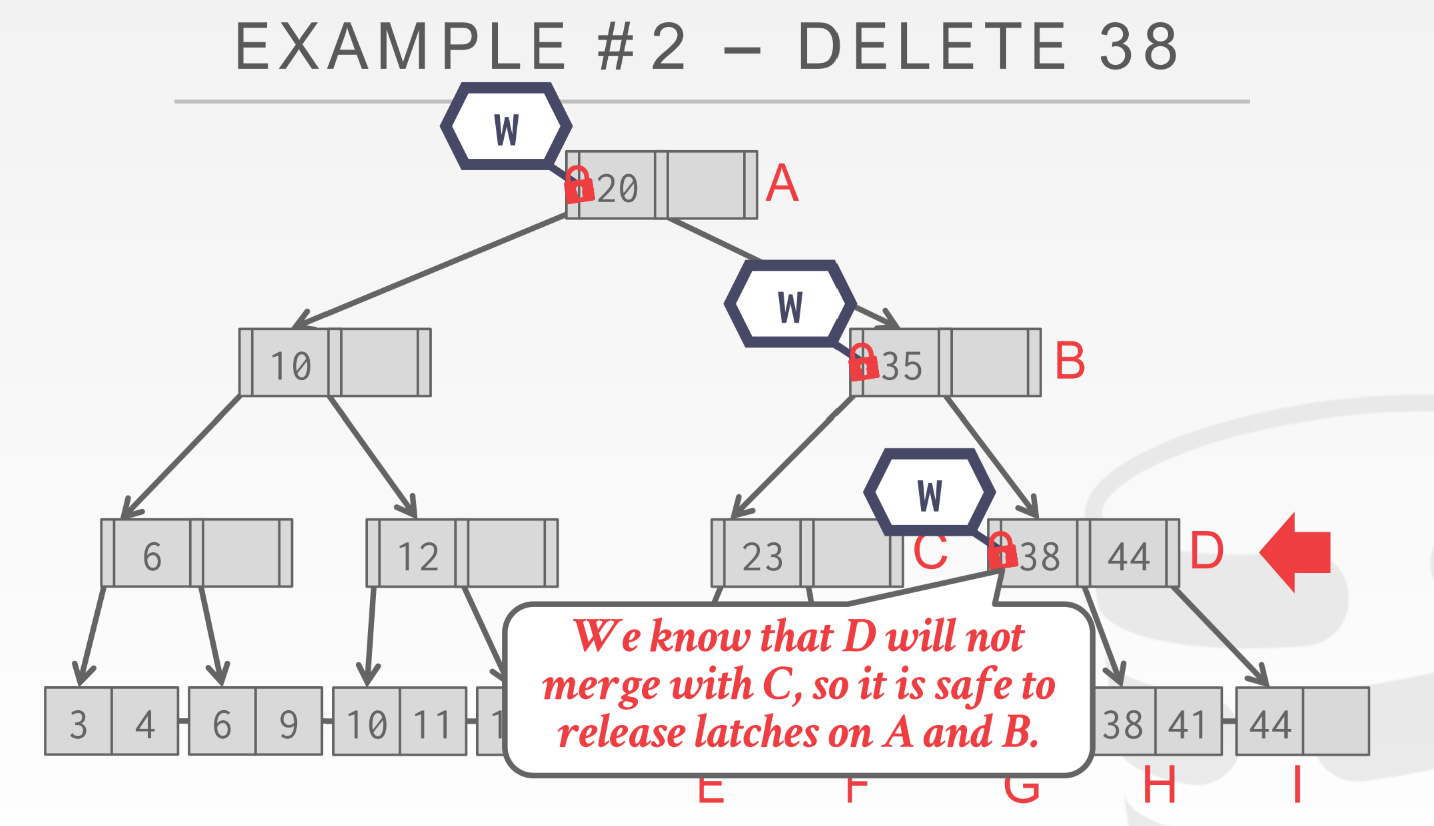
可见删除, 因为走到B的时候不确定这个page是否会coalesce, 万一要coalesce就有可能需要递归修改parent node的信息, 所以不能释放A的w latch, 直到走到D的时候, 因为D此时是满的, 就算删除一个也是半满不会引起coalesce, 也就是说D是safe结点, 因此这时候应该释放所有祖先wlatch;
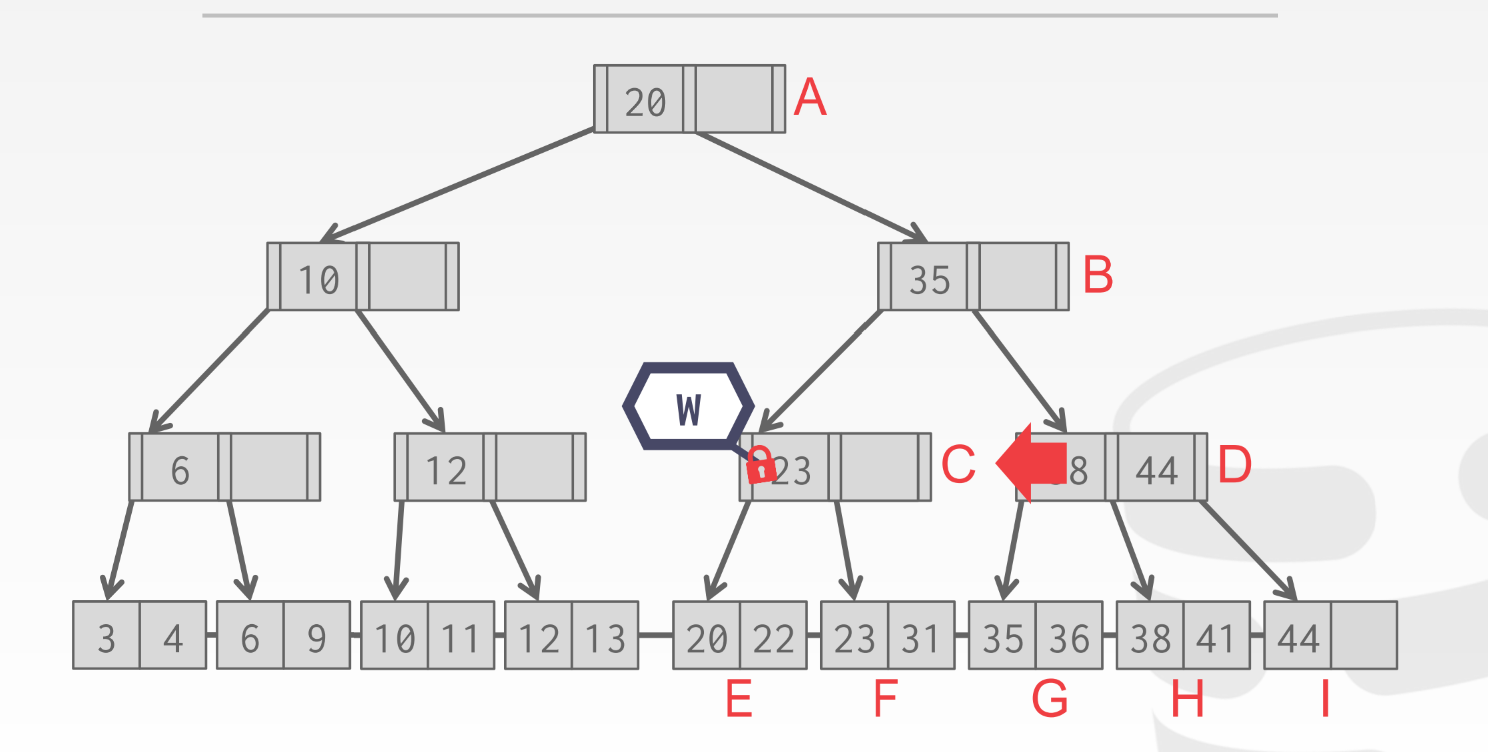
- 一开始拿A的wlatch, 再拿孩子B的wlatch
- 发现B不满, 因此对于插入来说B是安全的, 所以释放A的wlatch
- 因为25 < 35, 所以走左路, 拿C的wlatch, c不满, 所以c是安全的, 释放B的wlatch
- 25 > 23, 走第二个指针, 拿F的wlatch, 因为F满, 插入需要分裂, 涉及到C的修改, 所以不能释放C的wlatch
- 然后插入:
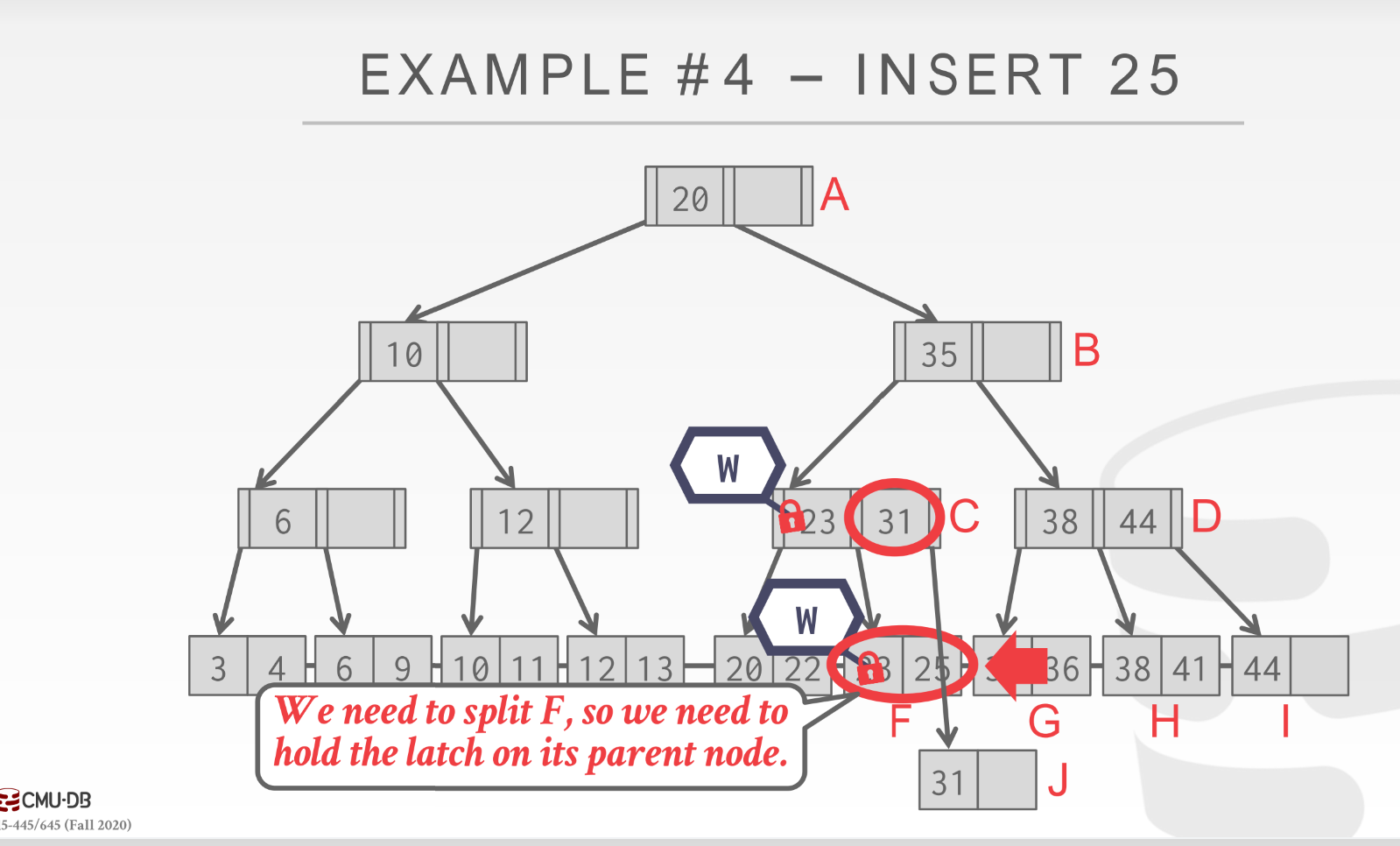
因为当前leafPage已经满了, 所以需要通过buffer pool new一个page, 然后把当前节点的31移动过去, 并且再父节点C中添加对应信息(这就是不能释放Cwlatch的原因);
上述策略虽然能有效得保证并发安全, 但是效率太低了, 因为插入删除一开始都拿了root得wlatch一直到第一个检查为safe node的孩子出现后才会释放root的wlatch, 而wlatch又是排他的, 任何读写操作都会被阻塞在获取root的w/r latch上, 成为整个B+tree的性能瓶颈!!!
蟹行协议改良
因为大多数对B+tree的大部分修改并不会刚好出发split或者merge(毕竟b+tree一页是4kb, 没那么容易就刚好在阈值上活动), 所以相较于前面协议总是加wlatch, 我们可以乐观得总是使用rlatch走到孩子节点, 如果发现孩子是safe, 就给孩子加个wlatch就行, 如果不safe, 就用悲观策略重新遍历(即上面原始得蟹行协议);
改良后得协议:
- search和前面一样
- 插入删除:
- 往孩子走, 一路上就像search一样加rlatch, 释放父结点rlatch, 一直走到孩子, 然后给孩子加wlatch;
- 如果孩子不safe, 那么第一次尝试是失败得, 释放所有锁, 重新从root开始一路获取wlatch(和前面一样);
This approach optimistically assumes that only leaf node will be modified; if not, R latches set on the first pass to leaf are wasteful.
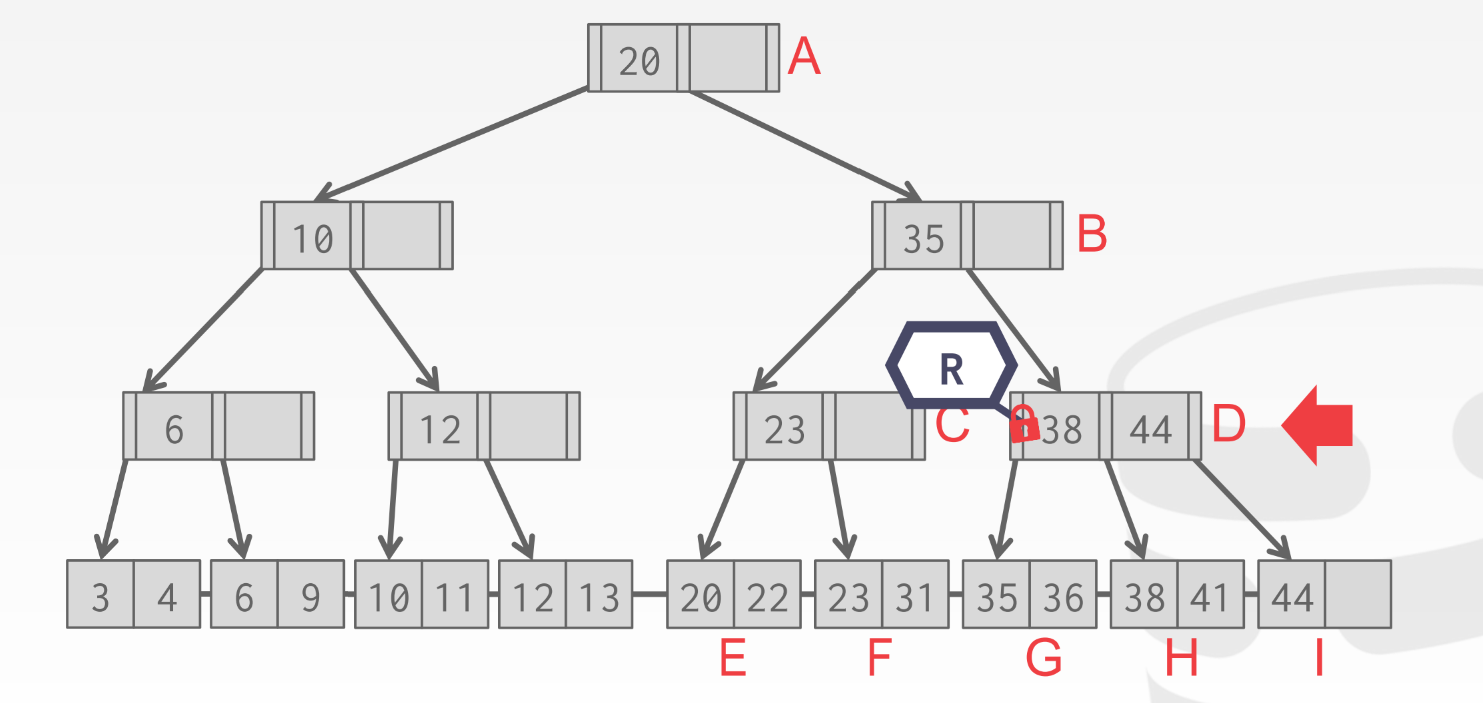
上图删除38:
- 我们先一路拿读锁, 所以同时最多持有2个latch(search过程一定会在获取孩子latch后释放parent的latch)
- 走到D, 然后拿孩子H的wlatch,走到孩子, 检查发现是safe node, 那么直接进行删除操作就行了;
同样上图插入25:
- 一路拿读锁到C
- 然后拿25所在结点的wlatch, 检查发现结点不安全
- 所有操作无效, 释放当前获取的所有锁, 从头开始悲观加wlatch;
move from one leaf node to another leaf node
上述所说的协议都是从root开始的, 但有时候, 比如范围扫描 我们需要从一个叶子节点通过next_page_id走到下一个叶子节点;
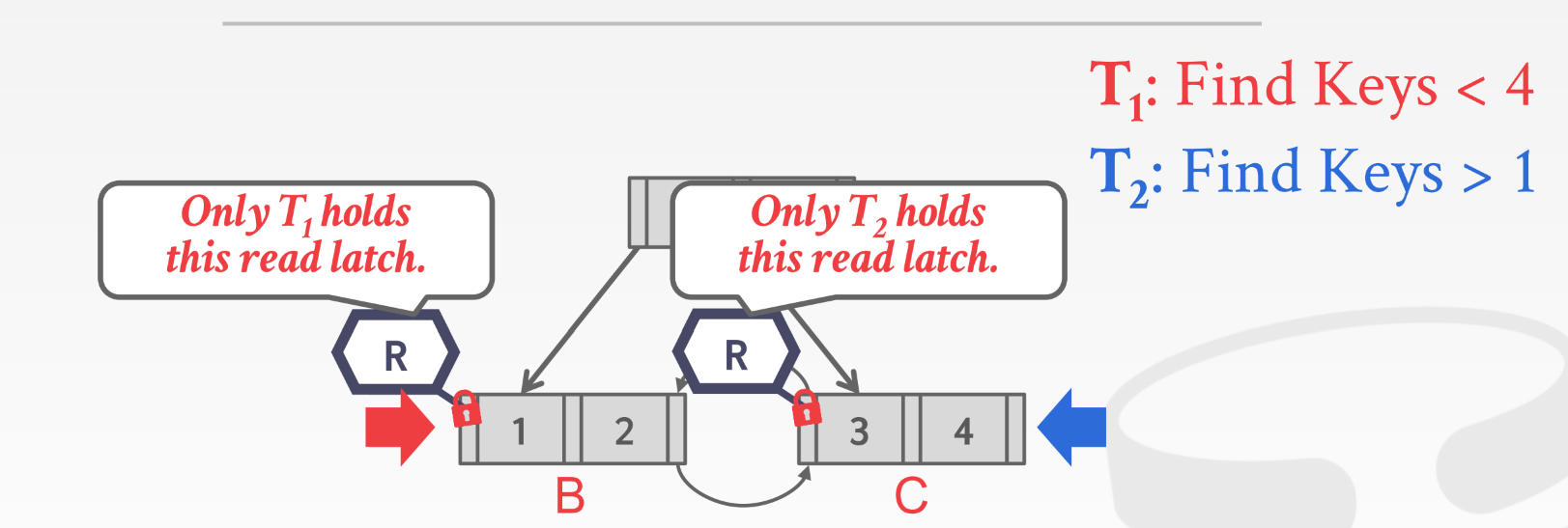
多线程都是读的情况下当然没有问题, 都能够获取相应的rlatch;
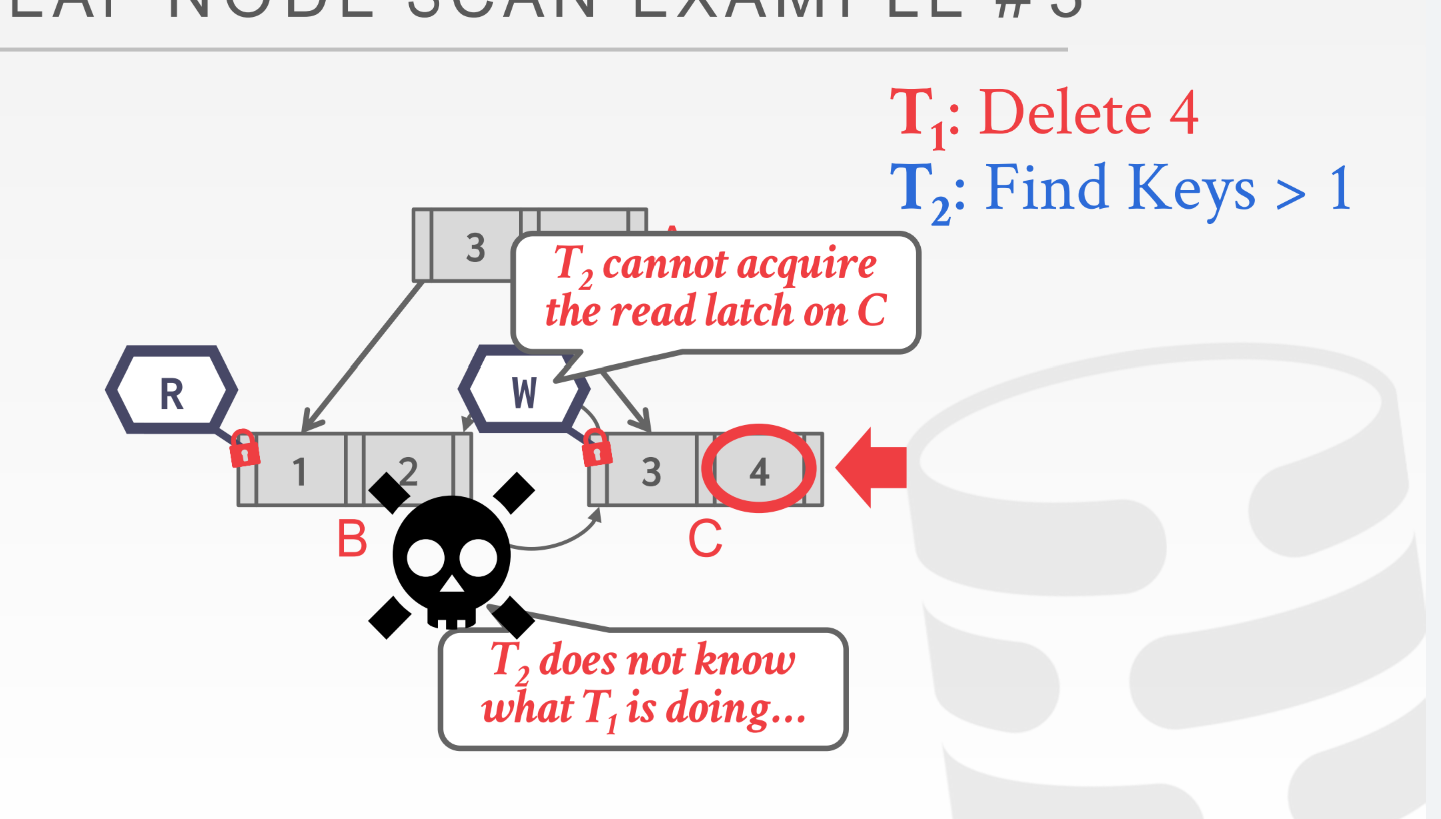
但是当读和修改一起的时候就有问题了, 因为读的线程不知道写的线程到底把隔壁结点怎么样修改了..

- latch是不支持死锁检测与避免, 唯一解决这个的办法就是编码的时候
延迟父节点更新:
每次一个leaf node满得时候, 至少要修改3个结点:
- 当前leaf
- 新建leaf
- 父节点
Blink-Tree Optimization: When a leaf node overflows, delay updating its parent node.
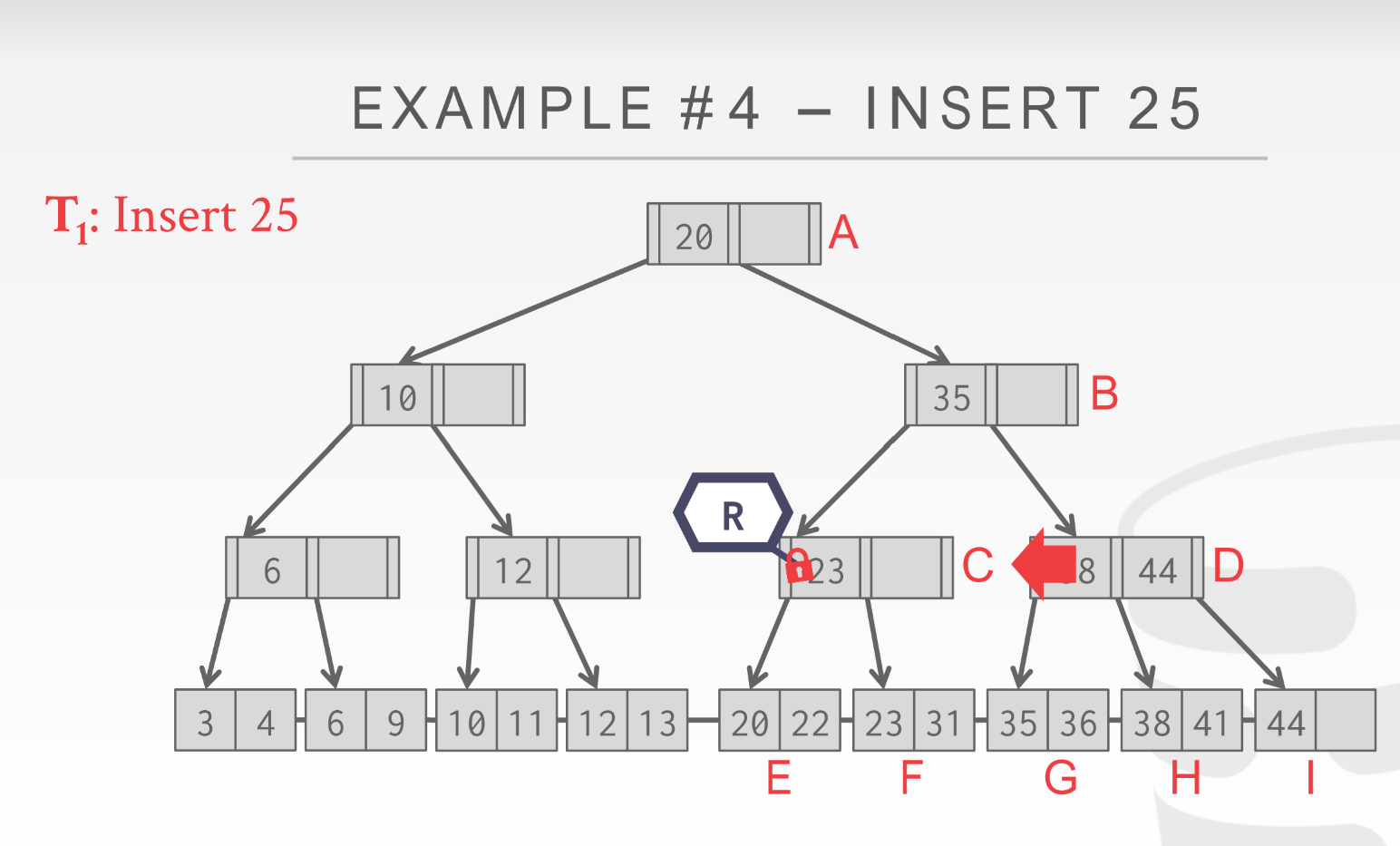
同样拿rlatch到c, 插入f, f满了分裂出新page, 这时候不修改parent C, 直接把新page->next_page id = f->next_page_id, f->next_page_id = 新page的page_id;
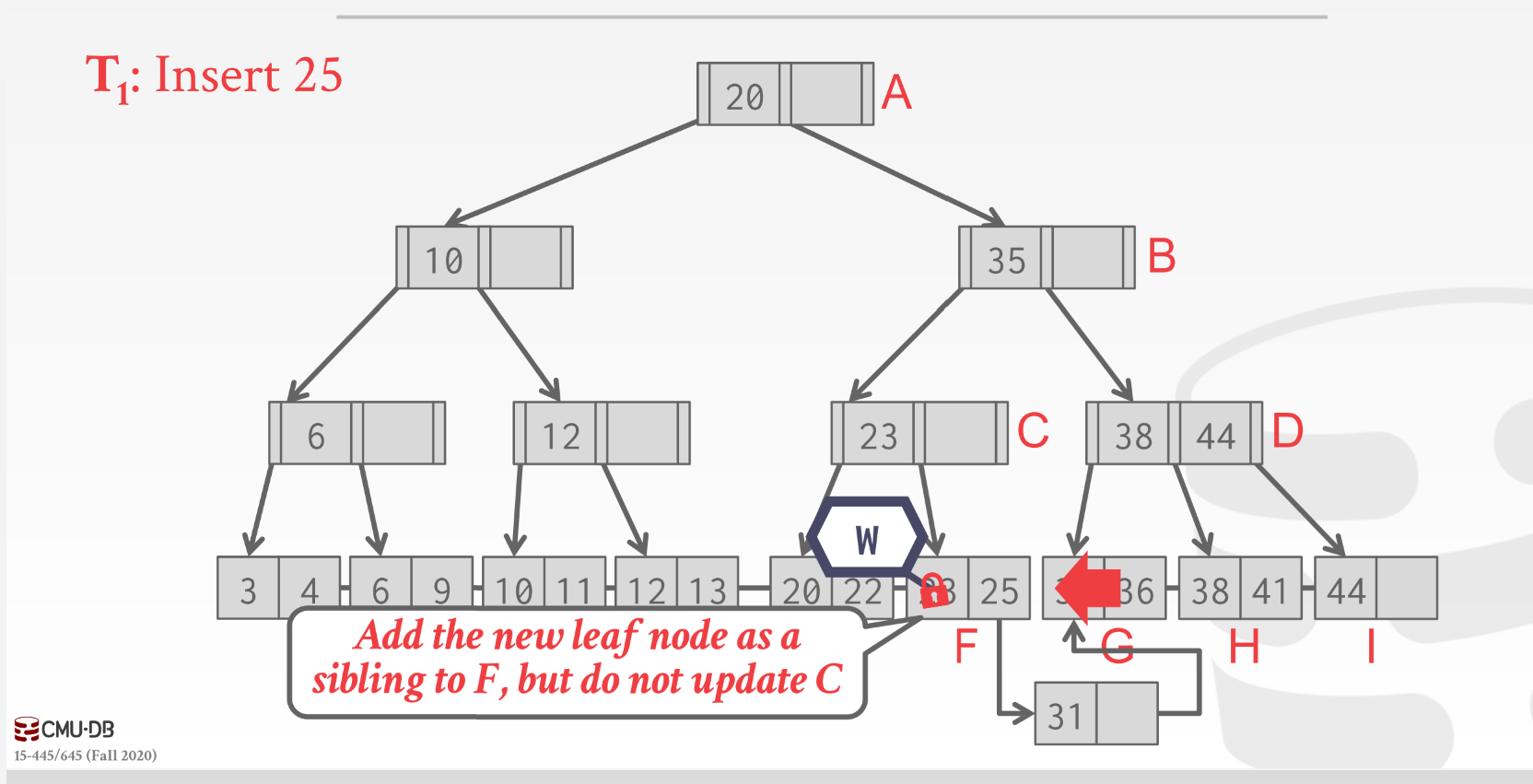
当下次在有线程拿到C的wlatch的时候再更新;
版本号latch:
