misc
昨天终于把proj1改到满分了, 终于可以放心得开始proj2了, proj2应该是整个项目中最难得部分, 加油!争取三天拿下!
The second programming project is to implement an index in your database system. The index is responsible for fast data retrieval without having to search through every row in a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
specification
You will need to implement B+Tree dynamic index structure. It is a balanced tree in which the internal pages direct the search and leaf pages contains actual data entries. Since the tree structure grows and shrink dynamically, you are required to handle the logic of split and merge.
proj2第一部分不需要管transaction指针; task4需要管这个指针;
checkpoint1
TASK #1 - B+TREE PAGES
需要实现如下三种page:
- B+ Tree parent Page:
- This is the parent class that both the Internal Page and Leaf Page inherited from and it only contains information that both child classes share. The Parent Page is divided into several fields as shown by the table below.
包含:

- B+Tree internal Page:
- Internal Page does not store any real data, but instead it stores an ordered m key entries and m+1 child pointers (a.k.a page_id).
- Since the number of pointer does not equal to the number of key, the first key is set to be invalid, and lookup methods should always start with the second key.
- At any time, each internal page is at least half full. During deletion, two half-full pages can be joined to make a legal one or can be redistributed to avoid merging, while during insertion one full page can be split into two.
- 删除的时候两个半满的页需要处理, 可以合并或者重新分配**(问兄弟借结点)**,
- 插入的时候一页满了后需要分为两页
- B+Tree leaf Page:
- The Leaf Page stores an ordered m key entries and m value entries. In your implementation, value should only be 64-bit record_id that is used to locate where actual tuples are stored, 这点非常重要, tuple并不是放在叶子节点中的!!! 叶子节点只存储了key到rid的map, 实际的数据还要根据rid的page_id去buffer pool调用fetchPage, buffer pool则会直接在内存中或者从磁盘上调入内存然后把page的指针返回给你, 然后根据slot num读取对应的tuple;
- Leaf pages have the same restriction on the number of key/value pairs as Internal pages, and should follow the same operations of merge, redistribute and split.
- **Important:**Even though the Leaf Pages and Internal Pages contain the same type of key, they may have distinct type of value, thus the
max_sizeof leaf and internal pages could be different.

可见rid中包含了page_id和slot_num两个member, 显然size要比internal node单纯的page_id大, 所以max_size要小;
Each B+Tree leaf/internal page corresponds to the content (i.e., the data_ part) of a memory page fetched by buffer pool. So every time you try to read or write a leaf/internal page, you need to first fetch the page from buffer pool using its unique page_id, then reinterpret cast to either a leaf or an internal page, and unpin the page after any writing or reading operations.
每一个B+树page对应的是memory page的data(4096B)部分;
捕捉基本信息
1 | // define page type enum |
可见index索引page类型有两种:
- 叶子节点page: 类型为1;
- 内部节点page: 类型为2;
b_plus_tree_page
b_plus_tree_page类是internal page 和 leaf page的父节点, It actually serves as a header part for each B+ tree page and contains information shared by both leaf page and internal page. 这个类实际上充当了leaf page 和 internal page的header部分, 保存了一些这两种page都会有的信息;
格式:
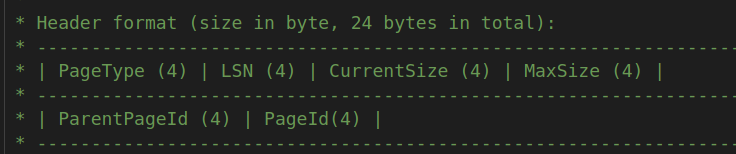
- 第一个pagetype表明是叶子结点还是内部节点
- 第二个lsn后续proj会用到
- currentSize表明当前page有多少个key-value pair;
- maxSize表示当前page最多能够放多少个key-value pair;
- parentPageId表明了在树的关系中父节点是谁. 根节点的parentPageID应该是-1?(已经按照-1实现);
- pageId表明了这个树的page(是memory page的data_部分)所对应的
memory page的page_id;
轻松完成
B+Tree internal Page:
最主要的一点就是他不存储任何真实数据, 只存储m个key和m+ 1个page_id; 但是我们是按照pair<key, page_id> 来分配空间的, 所以为了符合B+树的定义, 我们不使用第一个key的值!!! 查找总是从第二个key开始查.
然后比较麻烦的就是插入删除的合并和分割以及兄弟借结点.
- 因为我们会继承上一个类
B_plus_tree_page作为我们的header, 所以实际空用空间为4096 - 24B; #define INTERNAL_PAGE_SIZE ((PAGE_SIZE - INTERNAL_PAGE_HEADER_SIZE) / (sizeof(MappingType))), 这是官方给的页面maxSize计算公式 也就是可以存多少组mapping type, 不过感觉有点问题, 因为第一组实际上没有存储key啊. 不太懂.
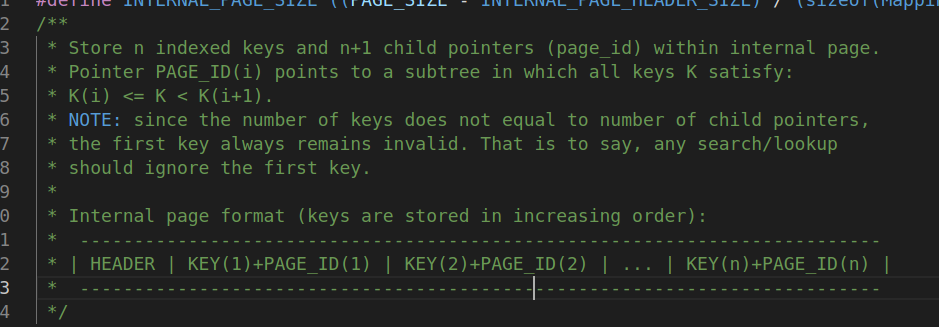
需要注意的就是:
- 结点内key需要是排序的, 这是递归定义的;
- 查找从第二个key开始;
- 但是第一个key和 page_id是怎么构造的呢???
- 创建一个新internal node, 必须要调用init函数
1 | // must call initialize method after "create" a new node |
B+Tree leaf Page:
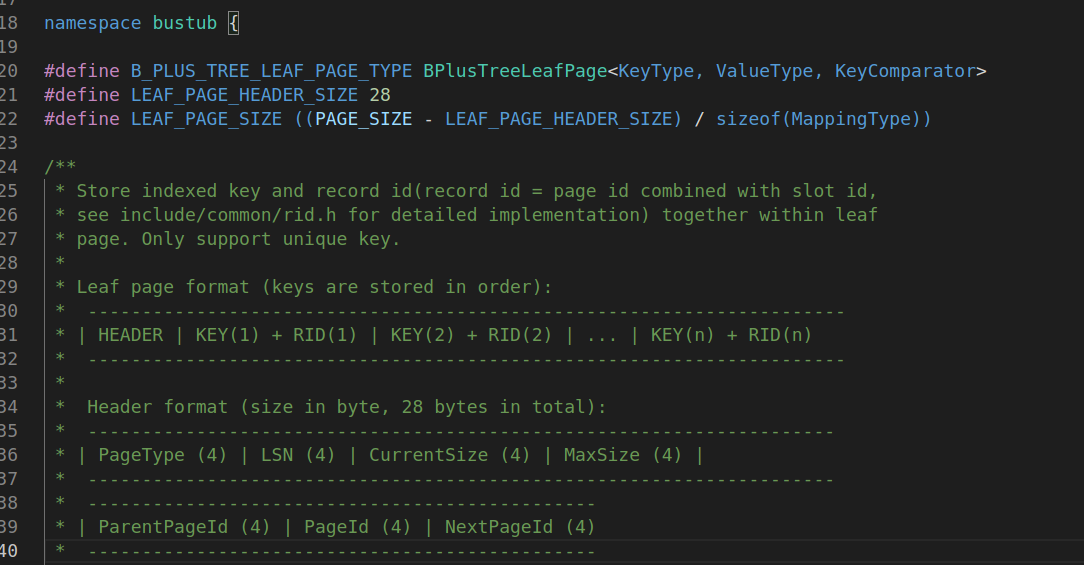
可见因为多了next_page_id这个指针, 所以header_size由24增大到了28;
总结
- 防卫式编程用
pragma once而不是IF_NO_DEFXXX; - 要使用enum类的内容:
return page_type_ == IndexPageType::LEAF_PAGE;