intro
这两节的ppt是关于B+树索引的, 会直接和proj2相关, 所以一定要学好.
索引是表的属性的一些排序了的子集(比如key)的replica(复制), 有了这个索引就能够快速找到tuple的位置.
DBMS保证表的内容和index的内容都是逻辑上同步的.
It is the DBMS’s job to figure out the best index(es) to use to execute each query.
There is a trade-off on the number of indexes to
create per database.
Storage Overhead
Maintenance Overhead
B+ Tree
B+树: 是一种自平衡的能够保持数据有序的树的数据结构, 能够保证查找, 顺序访问, 插入和删除的时间复杂度为O(logn):
- 是BST的一种推广, 可以有超过两个孩子
- 对于有大量数据块读写的系统优化
基本性质:
B+tree 是一个有如下性质的M路搜索树:
- 完美平衡(每个叶结点的深度都相同)
- 除了根节点之外的所有节点最少都是半满的(
M/2 -1 <= # of Key <= M - 1); - 任何一个有
k个key的内部节点有k + 1个非空孩子节点
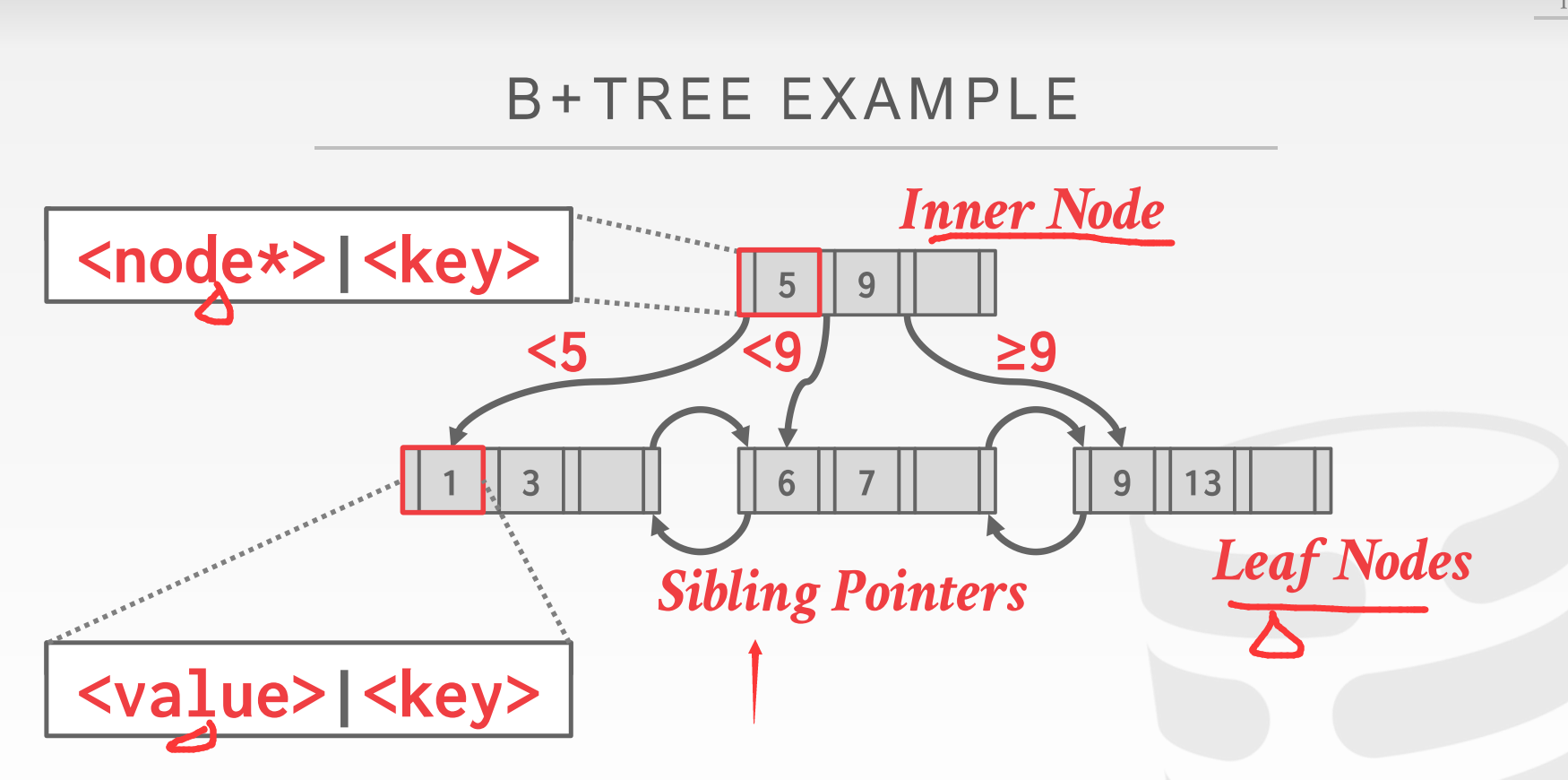
leaf node
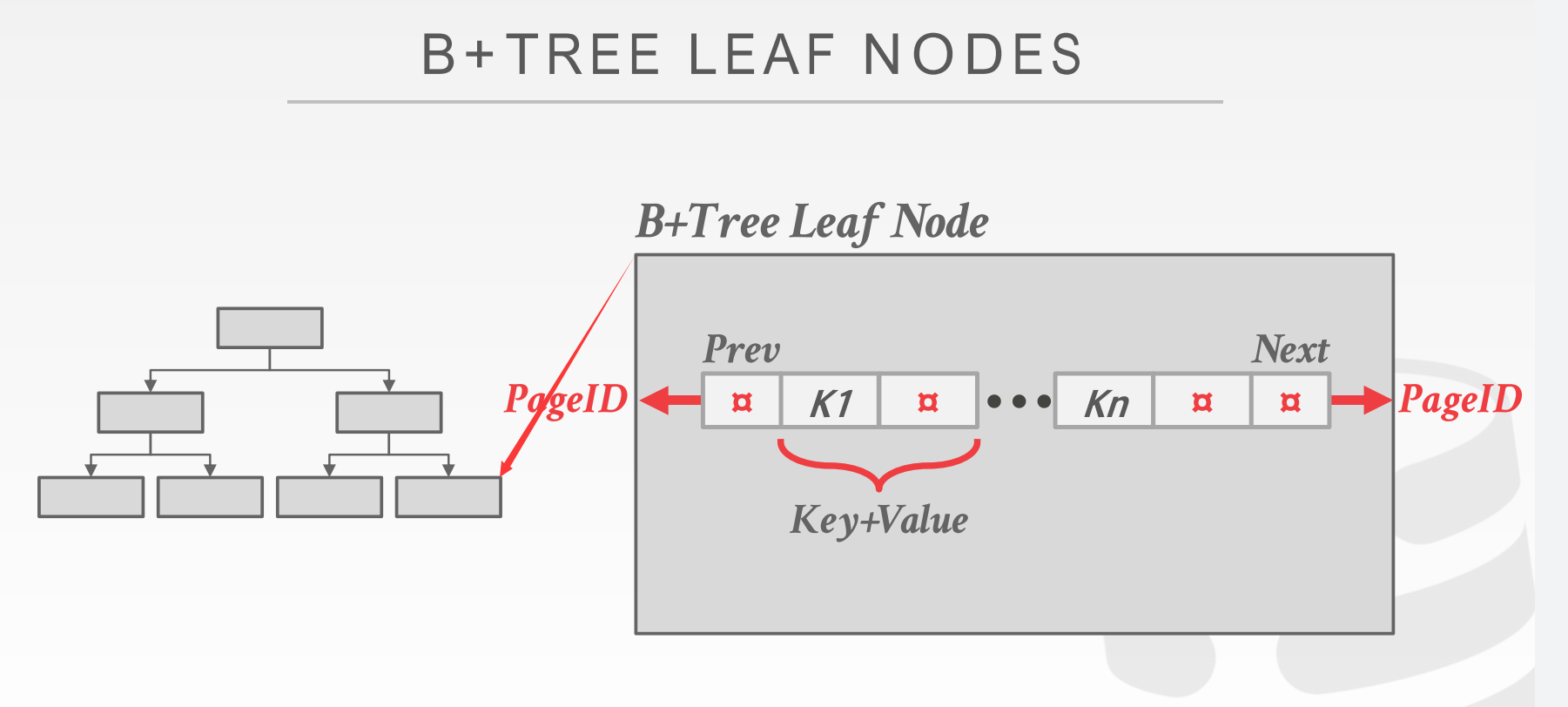
主要需要注意的是一个叶结点有指向前后叶结点的两个指针
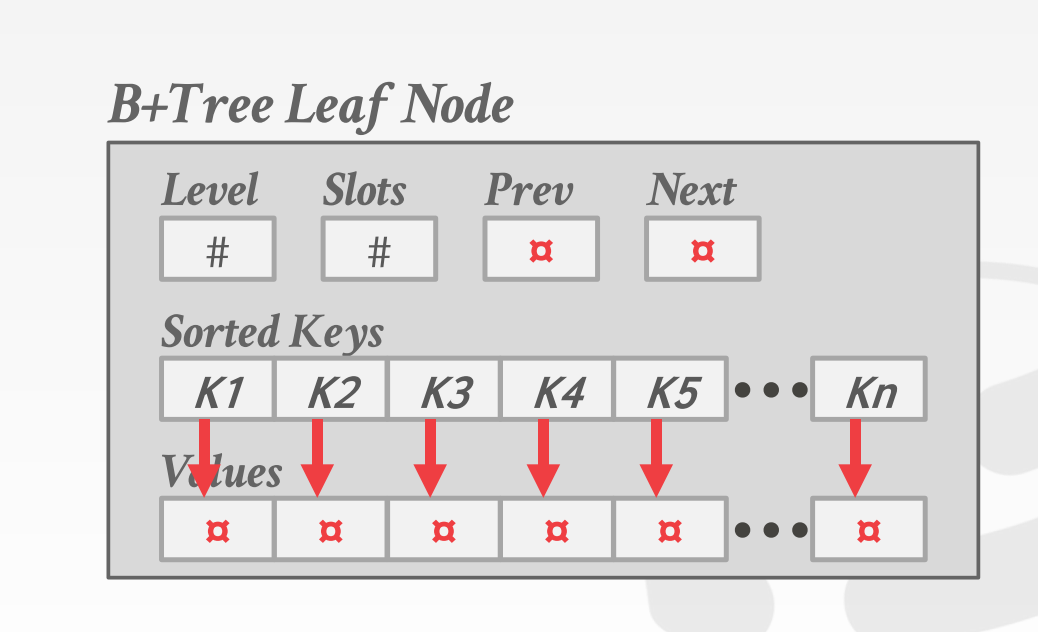
在我们实际实现中应该和上面这张图一样, 叶子节点并没有保存数据, 而是保存的key和page_id, 想要数据, 根据page_id去找buffer_pool拿就可以了, 所以指向前后叶结点的指针也不会放在leaf node中, 而是存放在具体page里面;
上图说到了leaf node实现的两种方式:
- 第一种就是我们上面提到的存储page_id;
- 第二种则是直接存储tuple data, 但是存储tuple data应该很难实现的..
和B树的区别:
The original B-Tree from 1972 stored keys + values in all nodes in the tree. More space efficient since each key only appears once in the tree.
A B+Tree only stores values in leaf nodes. Inner nodes only guide the search process.