intro
lab1也就是写一个buffer pool, 所以说这一节特别重要, 务必要弄懂!!!
database storage
spatial control: where to write pages to disk, the goal is to keep pages that are used together often as physically close together as possible on the disk;
Temporal Control:When to read pages into memory, and when to write them to disk.The goal is minimize the number of stalls from having to read data from disk.
上面两句化的意思就是:
- 空间上控制: 我们要让经常使用的page在disk上尽可能靠近, 可能和磁盘寻道有关?
- 时间上控制: 何时换入换出? 目标是为了减少IO阻塞, 所以我们应该充分利用局部性原理, 可以看到我们将在proj1中使用LRU算法, 因为该算法有很好的局部性;
同样示意图:
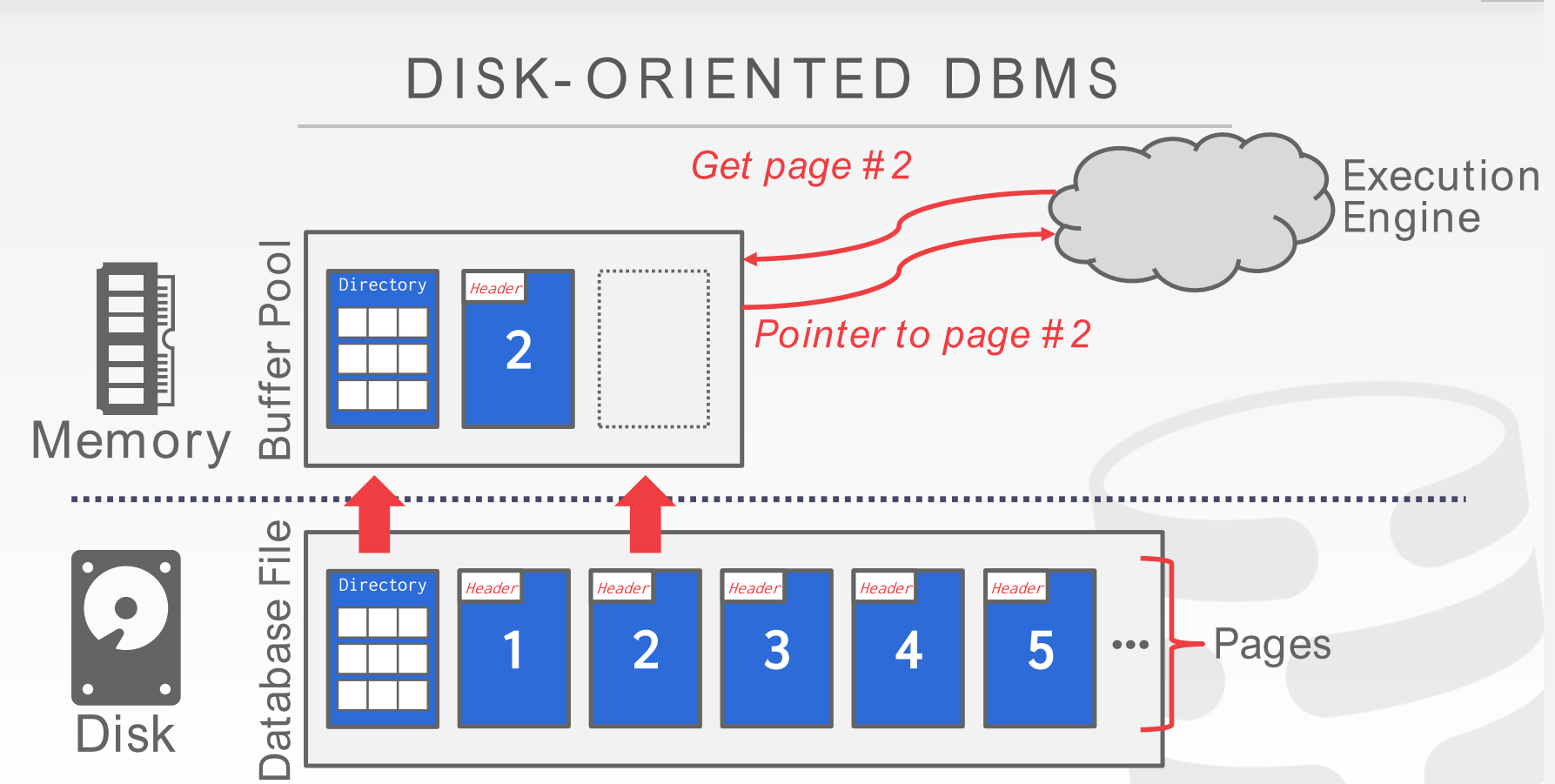
buffer pool organization

- 可看到
memory中有系列和一个page大小相同的内存区域构成的数组, 这些区域我们称为frame - 当需要的
page不在内存中的时候, 需要从disk中读page到memory中的一个frame, - 如果所有frame都被占用, 那么就涉及
victim一个frame - 而victim的frame不能是正在被线程使用的, 否则会引发错误, 因此我们需要有办法来表示一个内存中的frame存储的page是否正在被线程使用, 在被多少个线程使用
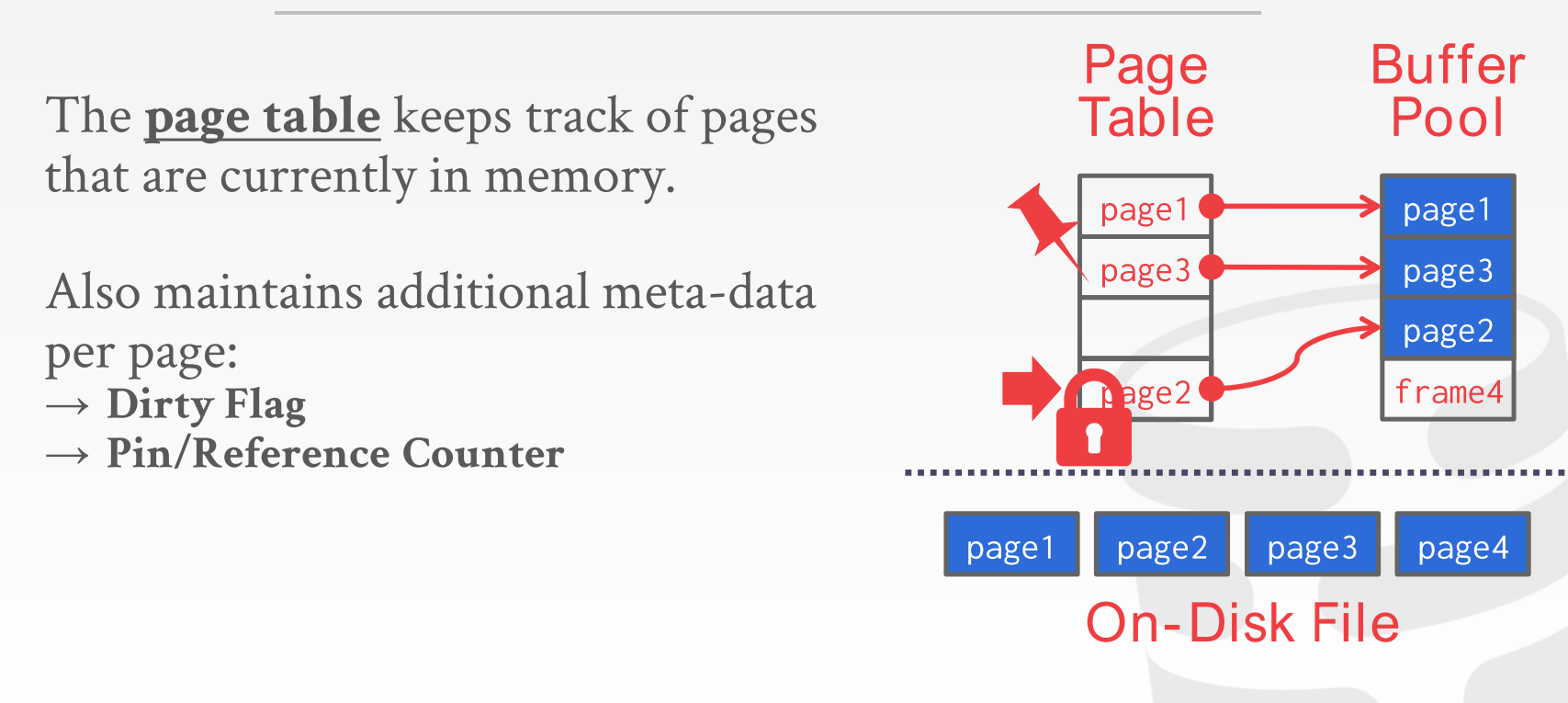
page table(不是操作系统的页表)负责保存在内存中的page(应该是保存id), 并且由一些信息表示这个page是否dirty(被修改), 有多少个线程正在使用这个page, 实现初步考虑可以如下:
1 | struct PageTableNode { |
page table中就存储Node, 具体使用什么容器还没想好, 此外还需要mutex;
lock 和 latch的区别

- lock:
- 对事务使用, 保护数据库的logical contents
- 在事务持续期间持有lock
- 需要支持回滚
- latch
- 保护多线程环境下dbms内部数据结构的
critical sections临界区 - 在操作期间持有
- 不需要支持回滚
- 保护多线程环境下dbms内部数据结构的
page table 和 page directory的区别

page directory如我们前文所说, 是用来组织disk上的pages的- 所以它保存的是各个page在disk上的哪个位置;
- 是存储在disk上的, 需要的时候读入内存, 然后根据这个page directory来去disk找到相应位置取我的page;
page table是用来组织内存中的pages, 它保存了page_id到frame位置的映射- 因此它是一个内存中的数据结构, 而且永远不需要被持久化, 毕竟断电啥的内存中page也没有了, page table也就没有存在的意义了;
- 通过上两点, 我猜测对一个page的访问应该先查
page table查看page是否在内存中:- 如果在则直接map到对应frame, 然后操作
- 如果不在则访问
page directory找到在磁盘中的具体位置, 然后发起磁盘IO;
buffer pool 优化
主要有四个方面:
multiple buffer pools
DBMS整个系统中并不是只有一个buffer pool, 它可以有:
- 多个buffer pool的instances
- Per-database buffer pool
- Per-page type buffer pool
这些操作可以减少latch contention 并且提高locality
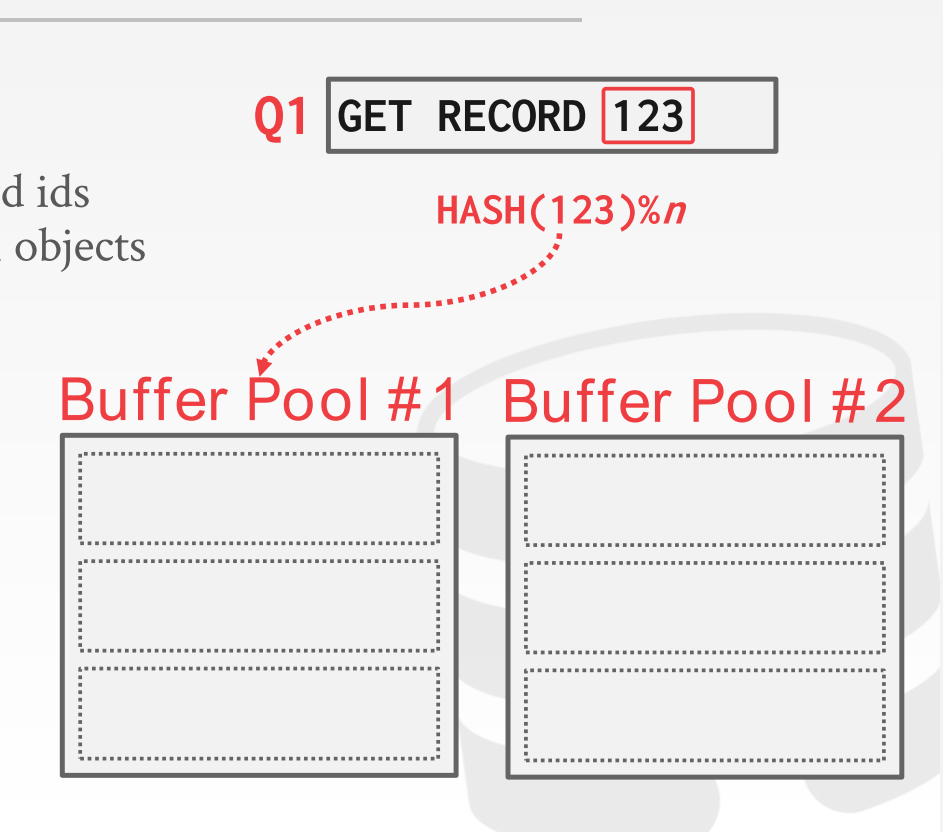
多个buffer pool的时候我读入一个page该往哪儿放呢?
- approach 1: Object Id:
- 在record id中加入一个object id, 然后维护一个从object id到具体buffer pool id 的mapping
- approach 2: hashing
- 直接hash page id 然后 取模
比较常用的应该是hash
pre-fetching 预取
DBMS可以根据query plan来预取一些page来提高性能;
query plan主要分为两种:
- sequential scans 线性扫描:
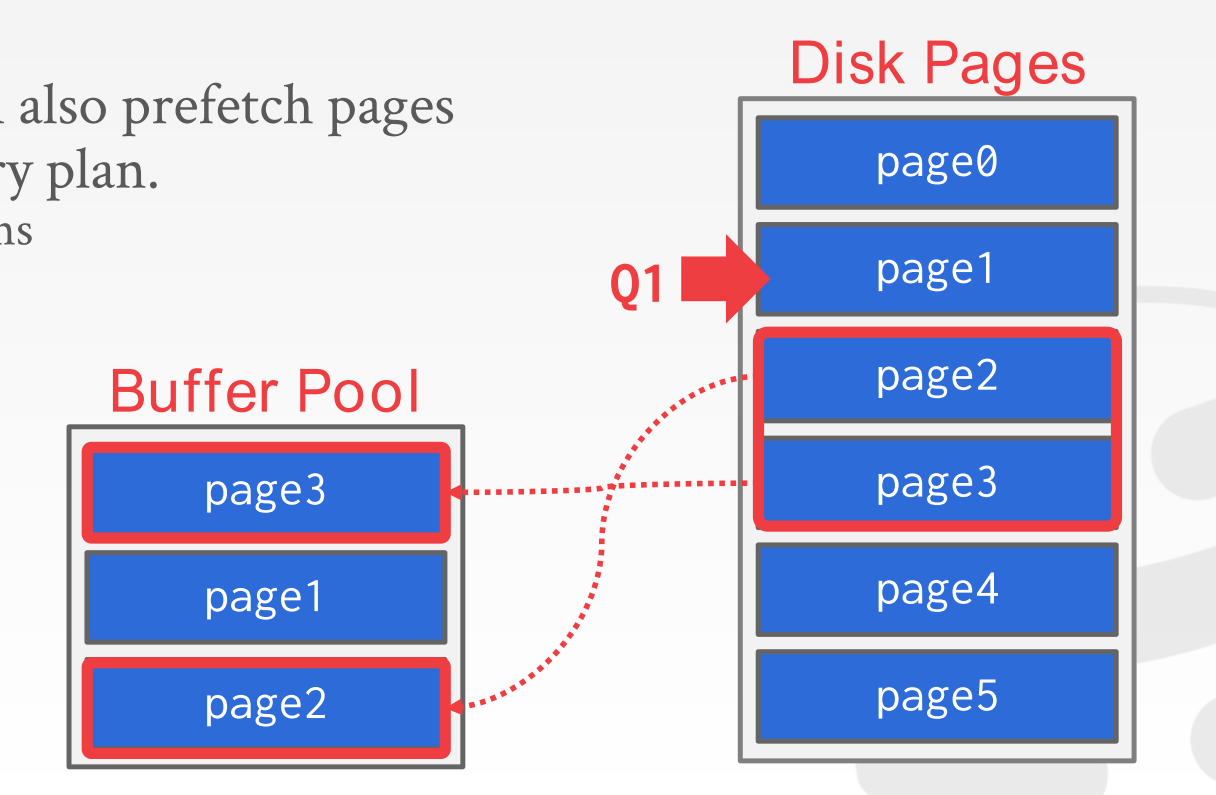
在线性扫描page的过程中, 扫到page1的时候, 从磁盘读page1进入内存同时或者之后会预取page2和page3进入内存buffer pool;
那么后面继续扫描page2 page3的时候就不需要再发起磁盘IO了, 提升了性能;
- index scan:
比如我们要执行如下语句:
1 | select * from A |
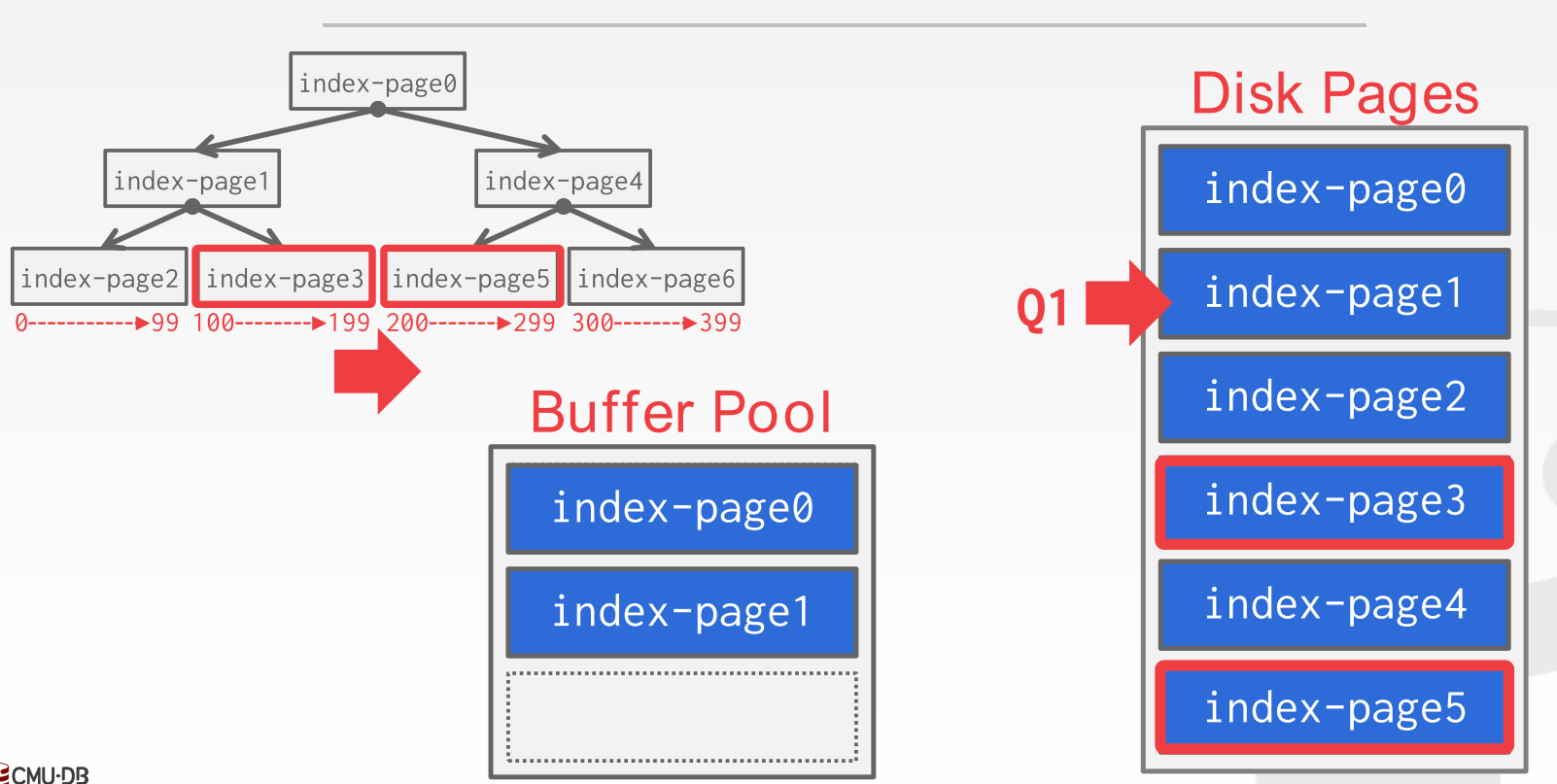
扫描到1的时候会预取page3和page5而不是page3和page4, 因为val 100 到 250 之间的值在这page3和page5上(怎么实现呢? 没想懂)
scan sharing
两种sharing:
- Queries can reuse data retrieved from storage or operator computations.
- 也叫synchronized scans
- 这和cache 结果是不同的
- 共用指针
- If a query wants to scan a table and another query is already doing this, then the DBMS will attach the second query’s cursor to the existing cursor.
- 我们有一个指针正在扫描, 如果另外一个任务要扫的是差不多的区域, 那么我们可以把这两个query在一起扫描;
- queries do not have to be the same;
- can also share intermediate results;
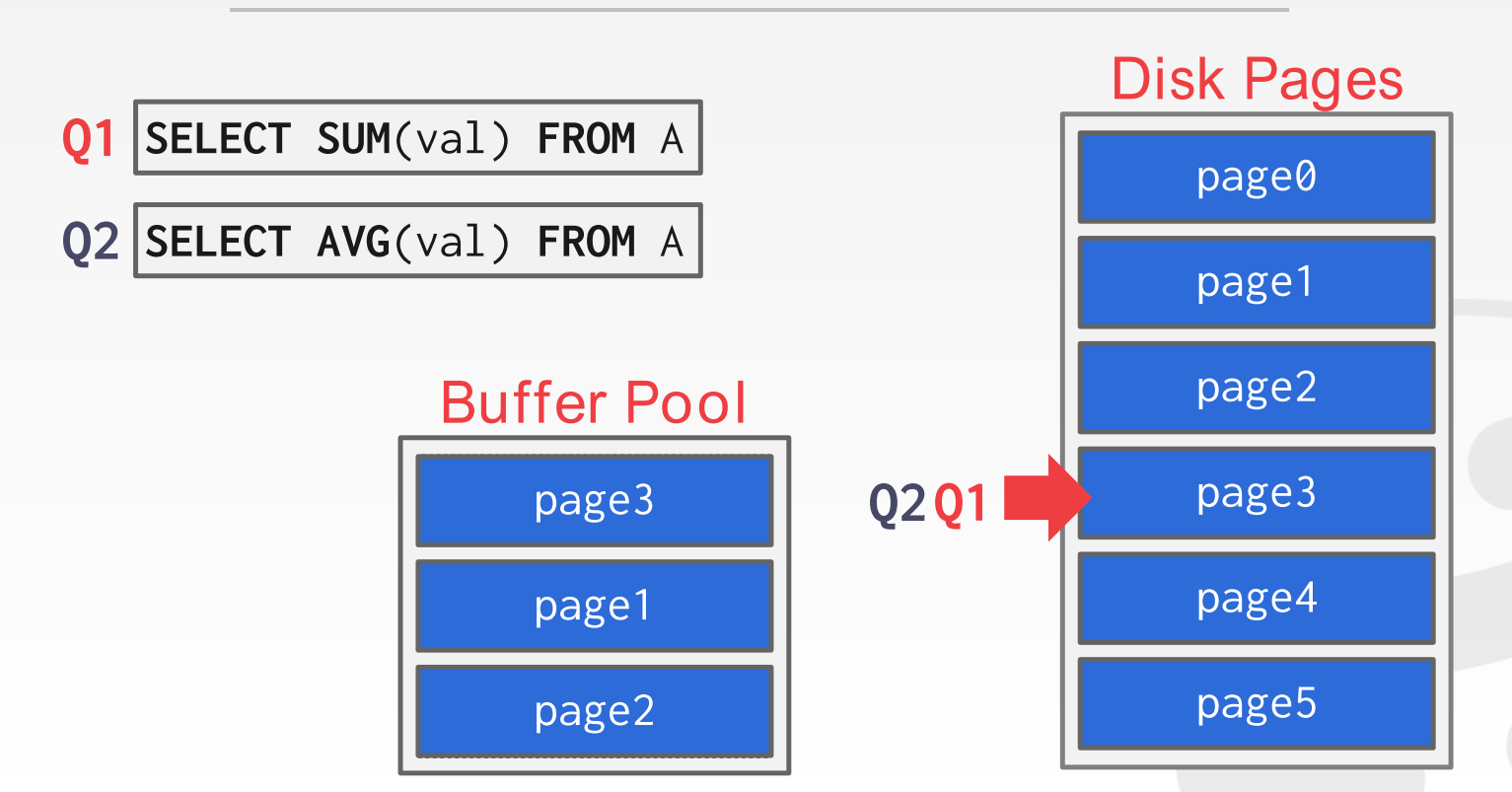
- 比如先执行第一条query, 扫描表A, 扫到了page3
- 然后这时候第二条query来了, 要求表A val column的均值
- 这时候不会新开一个cursor, 而是把这个query也使用第一个cursor, 一起从page3开始扫描起.
- 扫到page5, query 1完成, query2继续扫描怕page0, page1 和 page2;
buffer pool bypass
参考这篇博客, 一开始真似懂非懂https://blog.csdn.net/qq_42587089/article/details/111462035
为了避免过多的开销(访问hash table可能会带来较多的开销),为了避免污染现存的buffer pool(buffer pool中存储的数据在本次操作中可能不需要,但在不久的将来会非常需要,也就是说当前查询的局部性会导致buffer pool的全局性受到较大影响),在执行顺序性扫描操作时,系统不会将fetched page存储在buffer pool中。相反,系统会为该查询单独分配一小块内存。如果操作需要读取磁盘上连续的大量page,则此方法效果很好。Buffer Pool Bypass还可以用于临时数据(sort,join)。
大多数磁盘操作会走OS的api, os会maintain一个cache. 而对于dbms想要控制一切, 会绕过系统cache而使用直接IO(O_DIRECT), 这样的话可以定制自己的cache换出策略;
换页策略 LRU , Clock
当buffer pool满了还需要读入page的时候, 就需要用到换页策略, 因为我们要决定victim哪一个frame上的page; 主要需要考虑局部性原理
目标:
- correctness
- accuracy
- speed
- meta-data overhead
lru: least recently used algorithm
维护一个时间戳来表示每一页最后被访问的时间, 然后当dbms需要evict一个page的时候就evict timestamp最古老的那一页就行;
在实现的时候为了避免evict的时候还要sort来选, 可以直接在每次访问的时候都维护一个有序序列, 访问就把这个page放到最前面, 然后evict的时候直接换出最后一页就可以. 实际可以使用map + linkedlist来实现;
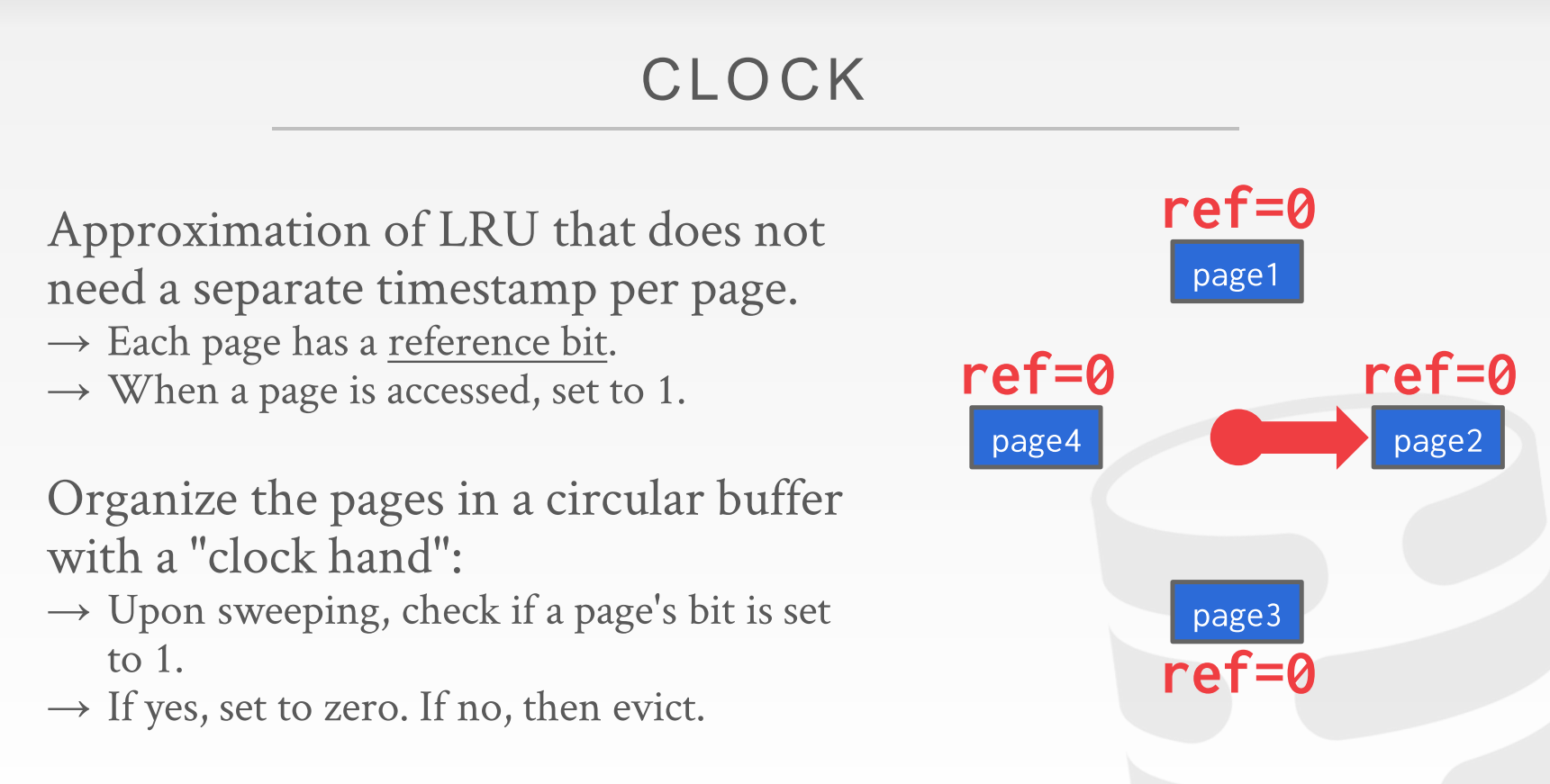
clock
Approximation of LRU that does not need a separate timestamp per page.
两种策略的缺点:
lru和clock都对于线性扫描没啥用, 容易受到顺序洪泛的影响:
- A query performs a sequential scan that reads every page
- This pollutes the buffer pool with pages that are read once and then never again.
In some workloads the most recently used page is the most unneeded page.
更好的策略: LRU-K
Track the history of last K references to each page as timestamps and compute the interval between subsequent accesses.
The DBMS then uses this history to estimate the next time that page is going to be accessed.
本地化(localization):根据每个txn /查询选择要逐出的页面
The DBMS chooses which pages to evict on a per txn/query basis. This minimizes the pollution of the buffer pool from each query.
优先级提示:允许txns告诉缓冲池页面是否重要
dirty page处理
如果一个页不脏, 那么DBMS可以直接丢弃它, fast;
如果一个页dirty, 那么dbms必须将它写回磁盘来持久化
DBMS可以定期遍历页表并将脏页写入磁盘。
当安全地写入脏页时,DBMS可以evict页面或者只是取消设置脏标志。
需要注意的是,在写入日志记录之前,我们不会去写脏页。


接下来开始写proj1, 先配置vim…