misc
算是正式步入这个课程的主题了, 这门课主要关心数据库底层的存储过程, 现在学的东西也会直接和lab1相关;
disk manager
存储层次:
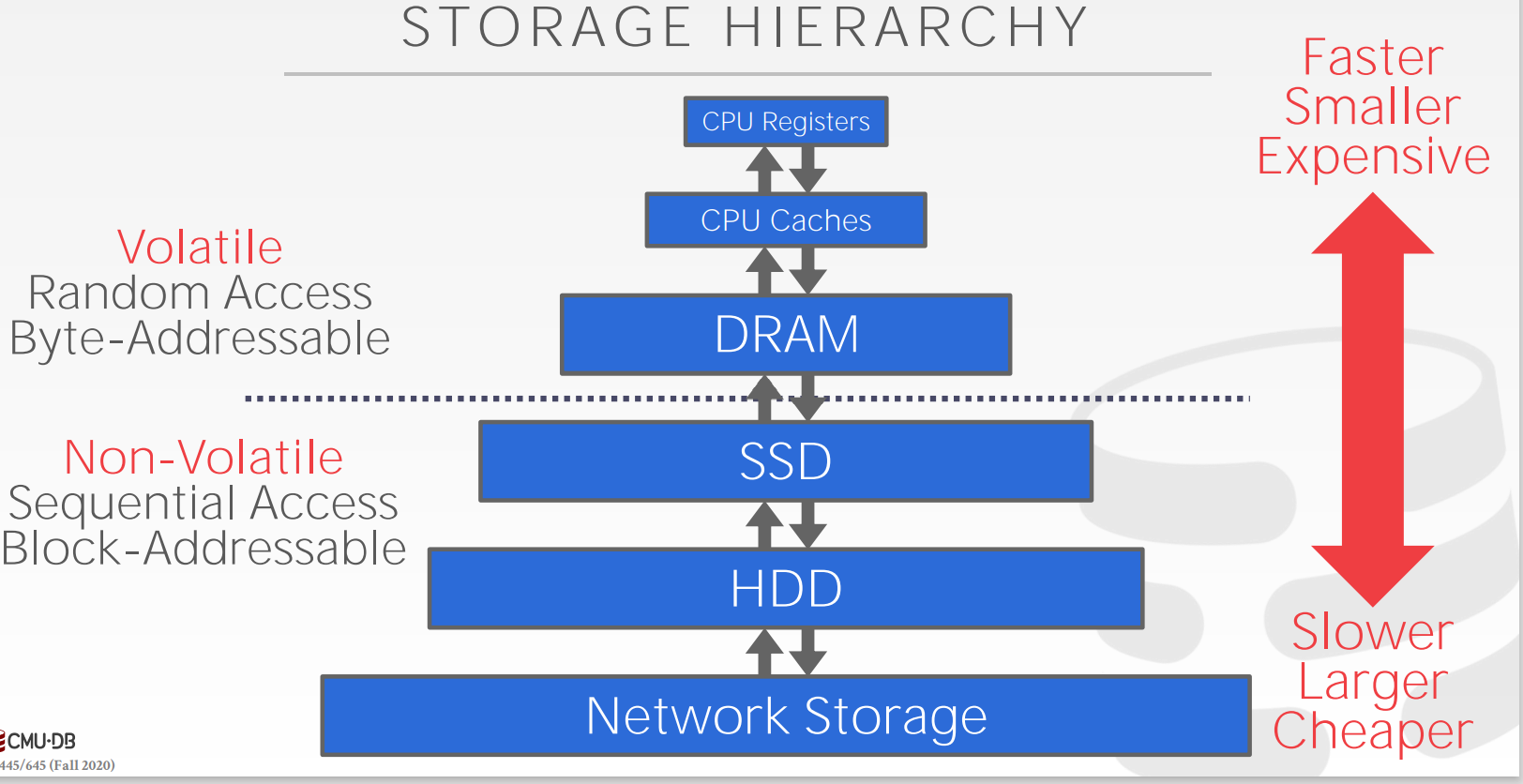
可见主要分为两部分:
- 上部分
volatile易失存储, 也就是断电后数据没了的, dram需要不断刷新. 包括内存,cache和寄存器, 老生常谈, 速度快, 贵, 容量一般小; 特征是:- volatile
- 随即访存
- 按字节编址
- 下部分
non-volatile非易失性存储, 不需要刷新, 断电后数据仍然存在, 包括固态硬盘,机械硬盘,网络存储, 老生常谈速度慢, 便宜, 容量一般大, 特征是:- non-volatile
- 顺序访问: 在磁盘上random access太慢了;
- 按块编址, 一般一个block是
512B;
- 每相邻两层之间都运用了局部性原理;
Disk-orientated architecture
- 这种架构下的dbms假设database的主要存储位置是在
non-volatile介质上; - dbms的组件负责数据在内存和磁盘之间的移动;
- dbms想要最大化对数据的顺序访问:
- 可以减少对随机
page写的算法, 这样的话数据存储在连续的blocks上; - 一次分配多个
pages作为一个extent(数据库区?)
- 可以减少对随机
系统设计目标
- dbms要能够处理大小超过可用内存的数据库;
- 磁盘读写很昂贵, 所以该系统要避免large stalls(啥意思? )和性能的降低;
random access在磁盘上比sequential access要慢, 所以dbms想要最大化顺序访问;
示意图
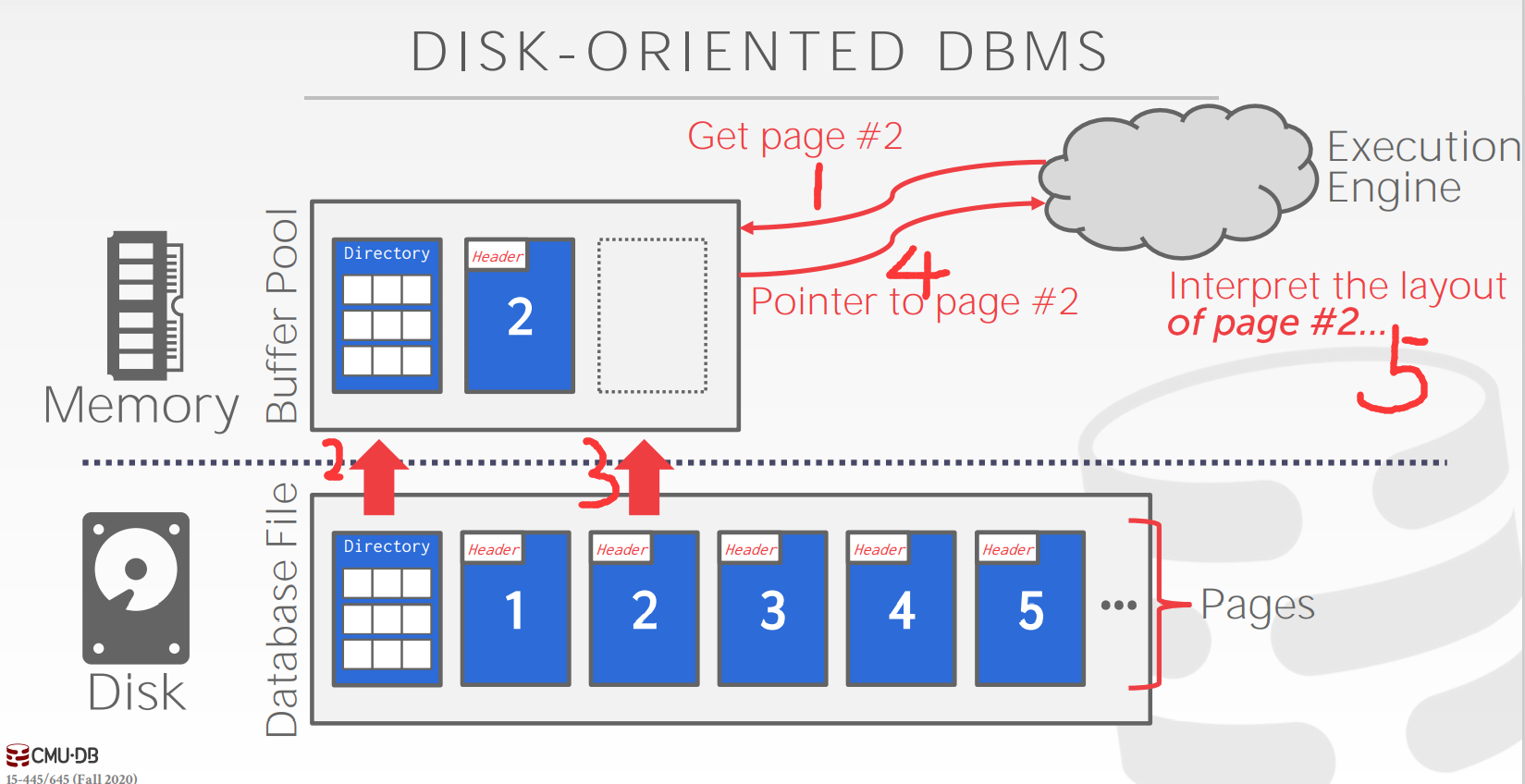
上图给出了整个系统的粗略示意,
- 可见一开始
execution engine想要获得page 2, 此时内存为空; - 从磁盘读入数据库的
directory page到buffer pool; - 从磁盘读入需要的第二页进入
buffer pool, 如果此时buffer pool已经满了, 还涉及到一些淘汰策略; - 然后
buffer pool给出指向第二页的指针给execution engine; execution engine有了指针后, 就能够对第二页的内同进行解析了;
- 可见一开始
为何不使用OS提供的mmap来管理?
操作系统提供的系统调用mmap - Wikipedia可以用来在内存和磁盘之间移动page, 那为什么我们不使用它来做数据库的一部分呢?
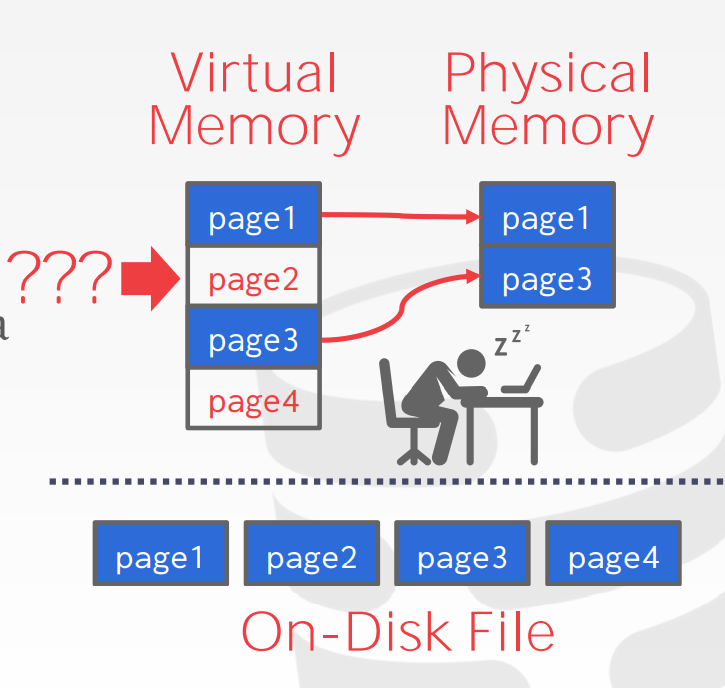
- 我们可以使用mmap映射进程地址空间中文件的内容,但如果mmap遇到页面错误,这将阻止进程,如果进程锁定了其他元组就麻烦了。
mmap对于read-only的访问确实够用, 但是当多线程写的时候情况就变得很复杂了;- DBMS总是想要自己来控制所有事情, 而且他能在如下方面比系统调用做得更好:
- 以正确的顺序向磁盘写脏页
- 专业prefetch 预取
- buffer替换策略, 我们会基于lru, 充分运用了局部性原理
- 多线程/进程的调度管理
- 操作系统不是你的朋友!!!
storage manager
storage manager负责维护数据库的文件, Some do their own scheduling for reads and writes to improve spatial and temporal locality of pages;- 它把这些文件组织成一些列的页
pages- Tracks data read/written to pages.
- Tracks the available space.
- 页是固定大小的数据块:
- 页可以包含
tuples,meta-data,indexs,log records.. - Most systems do not mix page types.
- 一些系统要求一个page是自包含的(self-contained);
- 页可以包含
- 每个页都会被给一个unique的标识符: The DBMS uses an indirection layer to map page ids to physical locations.
- 在DBMS中页有如下几种含义:
- 硬件的page: 通常为4kb, A hardware page is the largest block of data that the storage device can guarantee failsafe writes.
- 操作系统的page, 也是4kb
- 数据库的page,
512B - 16KB, sqlite为4KB, MySQL为16KB;
- database heap: 数据库中所说的heap是pages的无须集合, tuples是随机顺序存储的
- 支持create get write delete 页;
- 支持遍历所有pages, iterating;
- 两种实现heap file的方式:

linkedlist 实现 heap file, 有一个header page 存储了两个指针, 一个指针指向空闲page的链表表头, 另外一个指针指向使用了的page的链表表头; 每一个page都会保存他们还有多少空闲的slots的信息;

page directory实现heap file, dbms会维护一些directory pages, 这些directory记录了各个页在数据库文件中的位置以及每个page还有多少个free slots, 这种实现策略下, dbms必须懋征目录页和数据页是同步的, aka, 使用了一个页后要在directory中更新还有多少free slots类似的信息;
page layout

由上图可见, 每个页分为两个部分 header 和 data
header部分存储meta-data, 包括:
- page size
- checksum用来校验该页
- dbms的版本
- 事务可见性
- 压缩相关信息
一些系统比如oracle要求page是自包含的;
data部分则真正存储数据, 我们需要决定在page内如何组织我们的data, 主要有两种方式, 一种是tuple, 另一种是log;
Strawman给出了一个组织的idea, header只存储tuple的个数, 然后就在最后面append tuple:
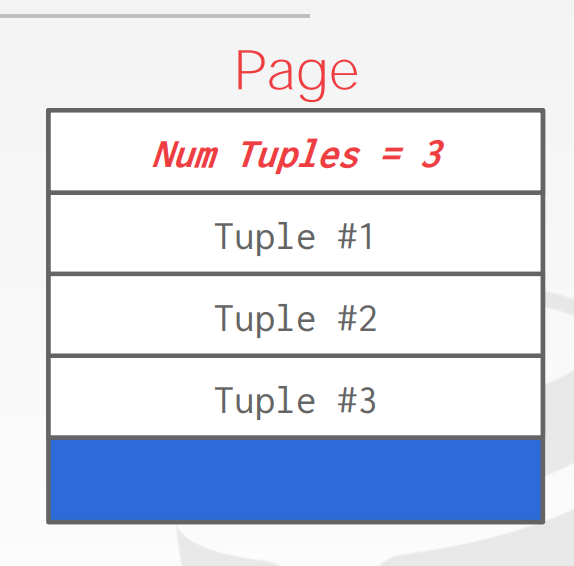
但这个方案显然有一些问题, 比如我删除了tuple2之后, tuple2的位置已经空了, 然后header上记录还有2个tuple, 那么我们可能会认为tuple2位置存储着第二个tuple, 实际上在第三个tuple; 另外这种方式也不适用于变长的属性attribute;
比较好的一种方案是如下图 slotted pages:
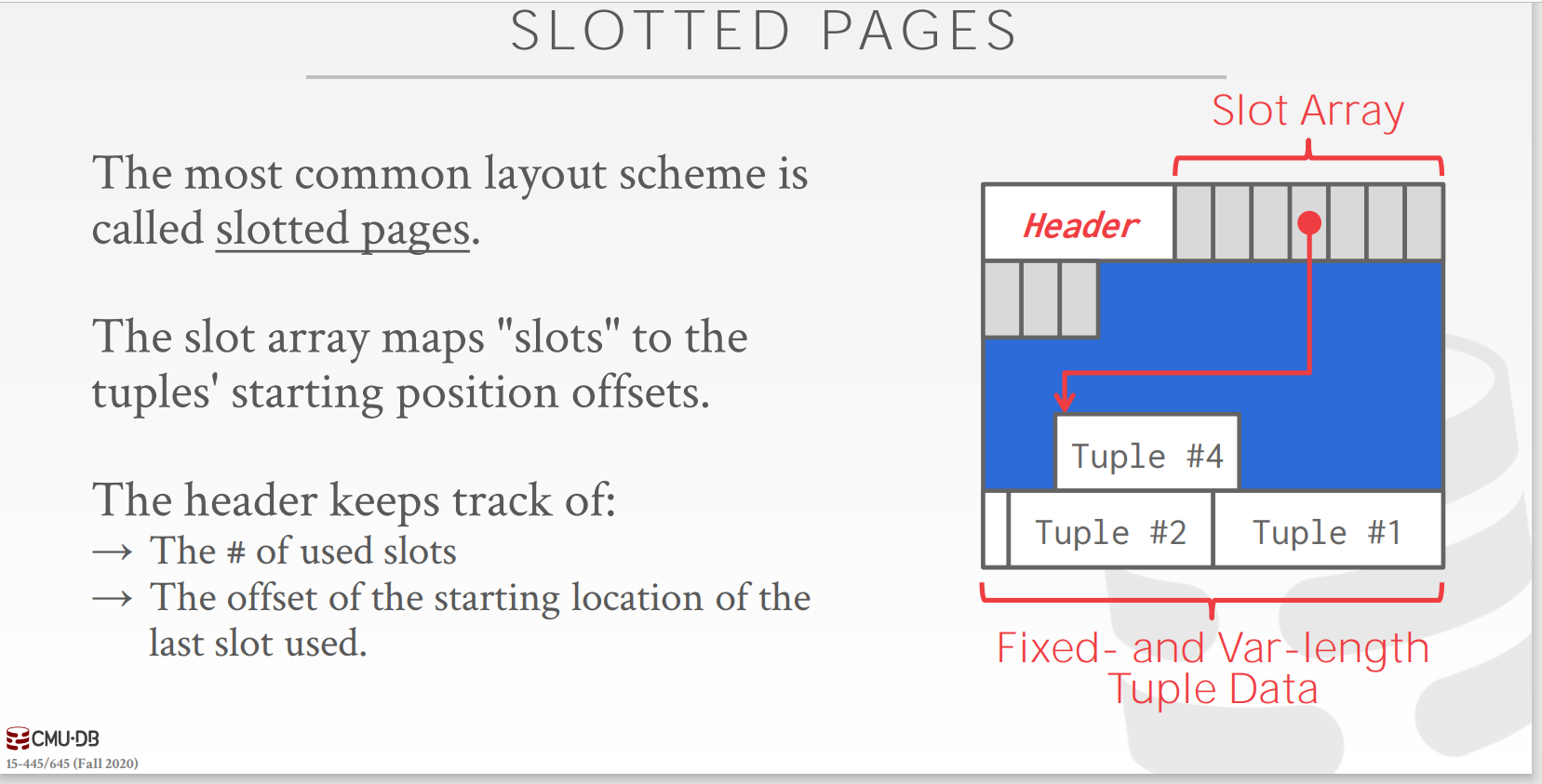
- 可见
slot array部分保存了每一个tuple的起始地址; - 可以看到
slot array从前往后, 而tuple则从page的最后面往前; header部分同样保存了一些meta信息, 包括已经使用的slots 数目, 以及最后一个tuple的其实地址offset;
record IDS: dbms需要能够找到每一个tuple的位置, 所以每个tuple需要被分配一个unique 的 identifier:
- 最常用的
ids:page_id+offset/slot; - 也可能包含文件location的信息;
- 但是一个应用不能过分依赖于这些ids;
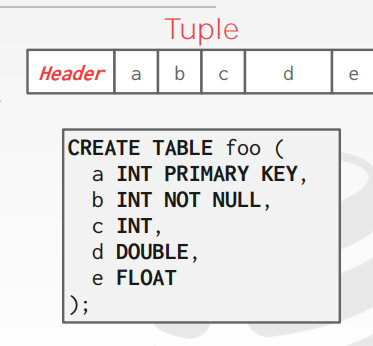
tuple layout
A tuple is essentially a sequence of bytes. tuple其实就是一个比特序列, 把这些比特序列解释为属性类型和值是DBMS的任务;
和page差不多, 每个tuple也有一个header存储meta信息, 包括
- 可见性(用于并发控制)
- BIt Map for null values;
- 我们不需要存储
schema的meta-data; - attributes都是按照
创建表时声明的顺序来存储的(由于软件工程的原因);
denormalize:

这页ppt没看太懂, 应该和proj关系不大;
总结
- Database is organized in pages.
- Different ways to track pages: linkedlist 和 directory
- Different ways to store pages: slot pages
- Different ways to store tuples